これから研究を始める高校生と指導教員のために 第2版
探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方
(これ研)
副読文書
******* III. ExcelのファイルのRへの読み込み方 *******
(「これ研」本文の第3部5.3.4項;p. 110)

本章では、解析用のファイルのExcelでの作り方とRへの読み込み方を説明します。その内容は、「これから研究を始める高校生と指導教員のために 第2版;探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方」(これ研)の第3部5.3.4項(p. 110)をより詳しく説明したものです。説明画面の多くはMacのものを使っています。Windowsでは少し表示が異なるかもしれません。R, RStudioのバージョンによっても異なるかもしれません。
1. 解析用フォルダの作成
あなたのパソコンに解析用のフォルダを作りましょう。解析用のファイルを入れたり、Rの命令文ファイルや解析結果等を保存するためのフォルダです。要は、新規のフォルダを作成し、それを解析用に使うということです。
1.1 Windowsでのフォルダの作成
Windowsでの作成法を説明します。
あなたのドキュメントフォルダ内に解析用のフォルダを作ります。キーボードにあるWindowsキー(□が 4つ並んだキー)とEキーを同時に押して下さい。
画面1
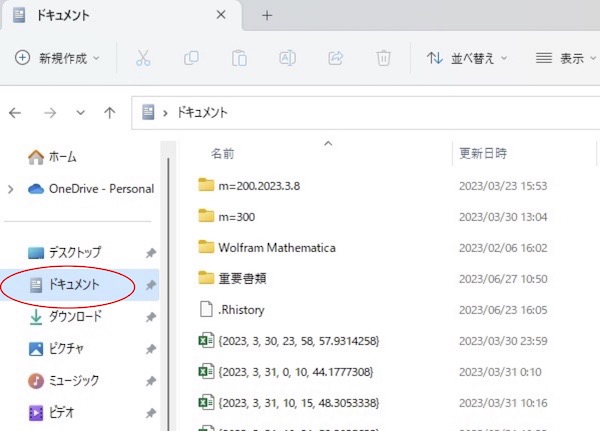
左の欄内に「ドキュメント」が現れます。それをクリックすると、ドキュメントの中身が右の欄内に現れます。ドキュメントフォルダ内の、解析用フォルダを作って入れておきたいフォルダを探し出します。ドキュメントフォルダ内のどれかのフォルダ内に入れるのではなく、ドキュメントフォルダに直に入れてもよいです。
「これ研2版」というフォルダ内に解析用フォルダを作りたいとします。
画面2
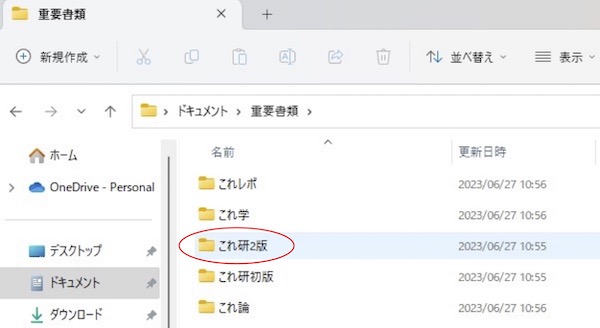
「これ研2版」フォルダを出してダブルクリックして開きます。
画面3
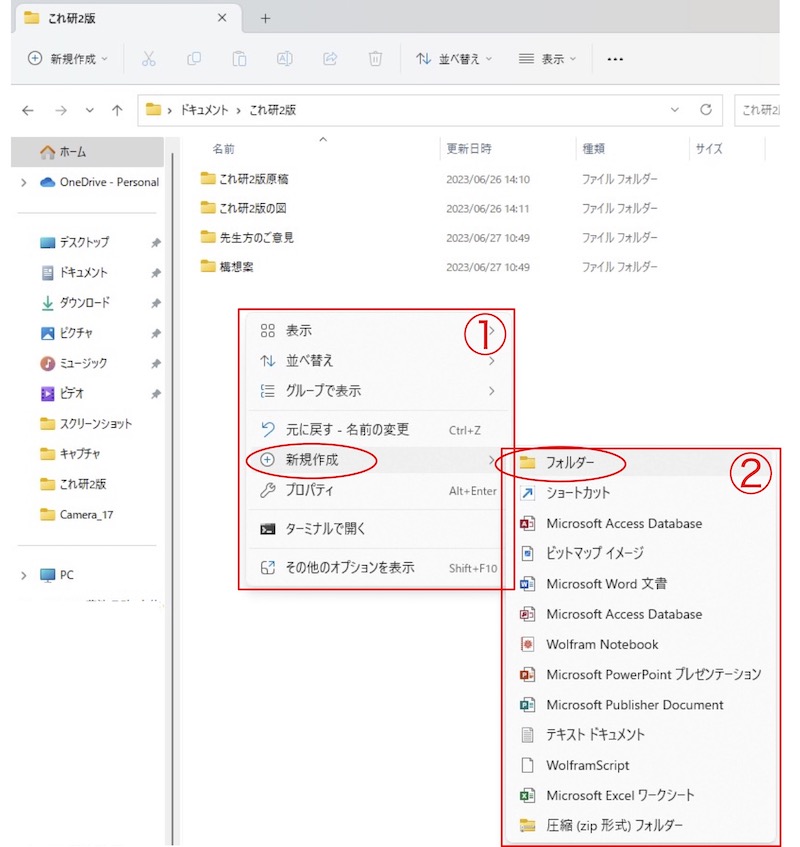
灰色の縦線の右側(赤枠があるところ;実際の画面に赤枠はありません)に「これ研2版」フォルダの中身が現れました。このフォルダ内で右クリックをすると、①の四角い赤枠で囲まれた部分が現れます。「新規作成」を選択すると、②の四角い赤枠で囲まれた部分が現れます。②の赤枠内の一番上にあるフォルダーをクリックして下さい。
「これ研2版」フォルダの中に新しいフォルダが作られます。
画面4
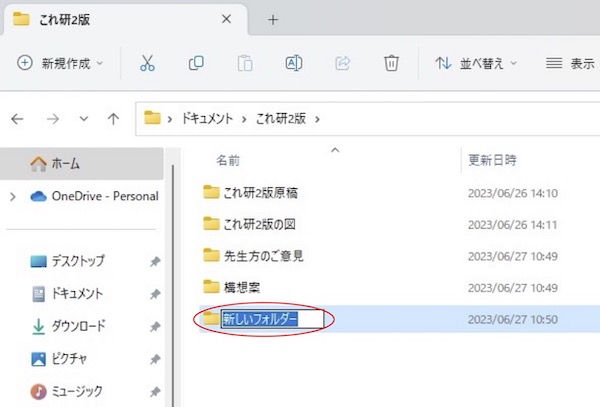
「新しいフォルダー」の部分をお好みの名称に変えて下さい。これで、あなたのドキュメント内に新しいフォルダが作られました。これを解析用のフォルダとして使います。
ドキュメントフォルダ内のどれかのフォルダ内に入れるのではなく、ドキュメントフォルダに直に入れる場合は、画面1の灰色の棒の右側で右クリックして下さい。画面3になりますので、上記の説明に従って保存して下さい。
1.2. Macでのフォルダの作成
Macでの作成法を説明します。
あなたの書類フォルダ内に解析用のフォルダを作ります。Dockが隠れている場所にカーソルを近づけてFinderを出してそれをクリックして下さい。
画面5

Finderが開きます。Finder内にウィンドウが開いていたら画面7の説明に移って下さい。
画面6
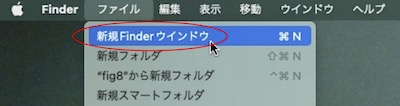
Finder内にウィンドウが1つも開いていなかったら、メニューの「ファイル」から「新規Finderウィンドウ」を選択します。
Finder内にあるウィンドウです。
画面7
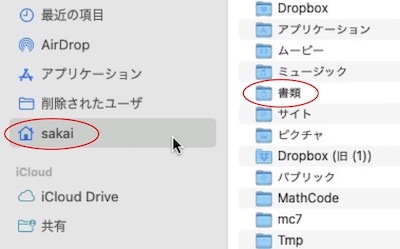
あなたのユーザー名(この画面ではSakai)をクリックして「書類」フォルダを出します。
書類フォルダ内の、解析用フォルダを作って入れておきたいフォルダを探し出します。書類フォルダ内のどれかのフォルダ内に入れるのではなく、書類フォルダに直に入れてもよいです。
画面8
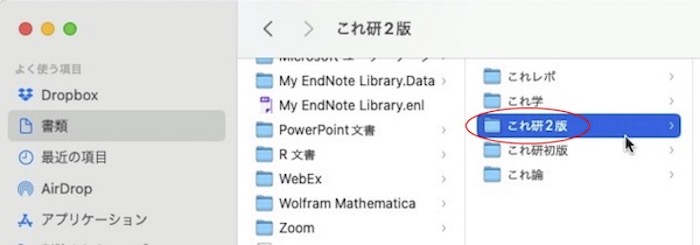
「これ研2版」というフォルダ内に解析用フォルダを作りたいとします。「これ研2版」をクリックしてこのフォルダを選択します(このフォルダがハイライトされています)。
「これ研2版」を選択した状態で、メニューの「ファイル」から「新規フォルダ」を選択します。
画面9
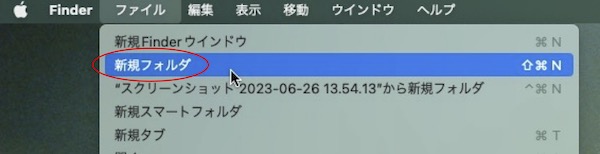
「これ研2版」フォルダの中に新しいフォルダが作られます。
画面10
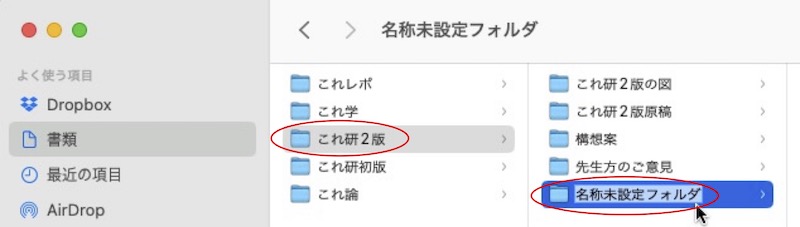
「名称未設定フォルダ」の部分をお好みの名称に変えて下さい。これで、あなたのドキュメント内に新しいフォルダが作られました。これを解析用のフォルダとして使います。
書類フォルダ内のどれかのフォルダ内に入れるのではなく、書類フォルダに直に入れる場合は、書類フォルダを選択した状態で、メニューの「ファイル」から「新規フォルダ」を選択します(画面9)。以降は、上記の説明に従って保存して下さい。
2. Excelでの、解析用ファイルの作成
Rで読み込んで解析するためのファイルをExcelで作ります。Excelを開いて、解析したいデータを入力します。各列の先頭行にその列のデータの名称を書き、2行目以降にデータを入れます。データに欠損値があっても構いません。ファイル中で日本語を使うと読み込みがうまくいかない可能性があります。日本語は使わずに、半角の英数字のみを用いるようにしましょう。
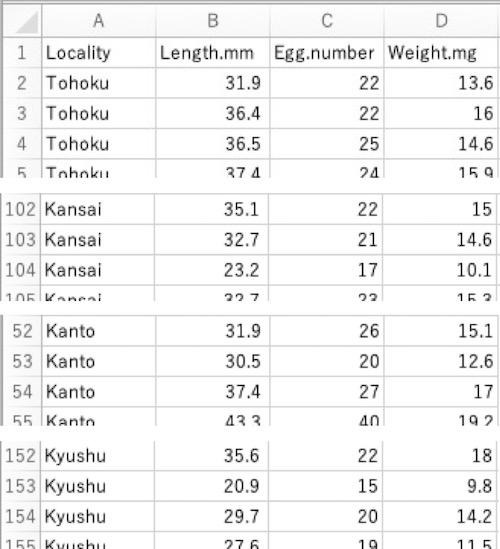
たとえば、東北・関東・関西・九州(Locality)の雌メダカ各50個体を対象に、体長(Length.mm)と体重(Weight.mg)と1個体1回あたりの産卵数(Egg.number)を調べたとします。それらのデータを下記のように書き込みます(これは架空のデータです)。
画面11
こうして作ったデータを、Excelのファイルとして保存し、元ファイルとして持っておきましょう。
画面12
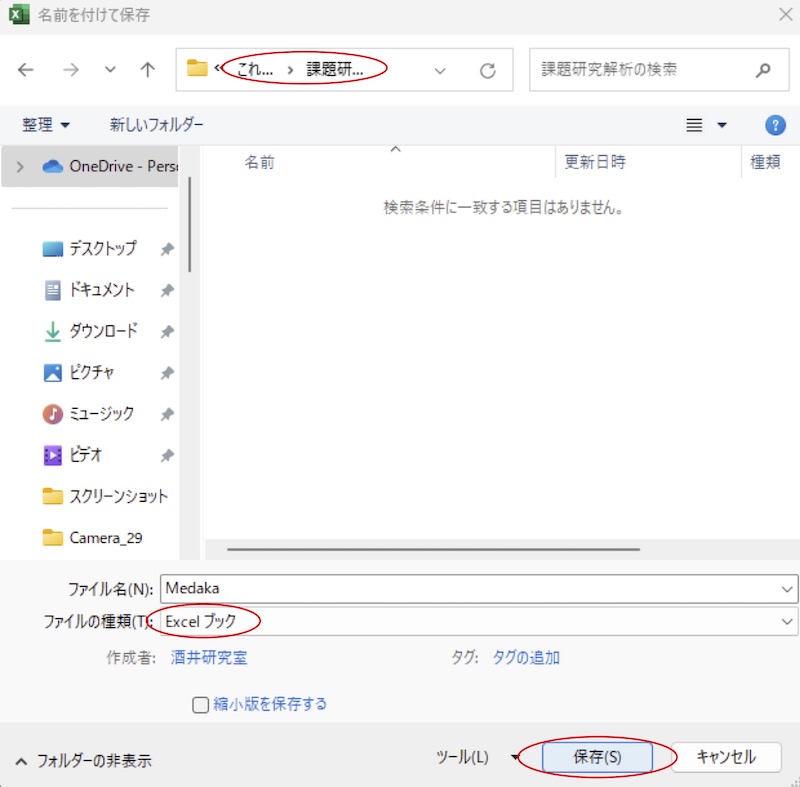
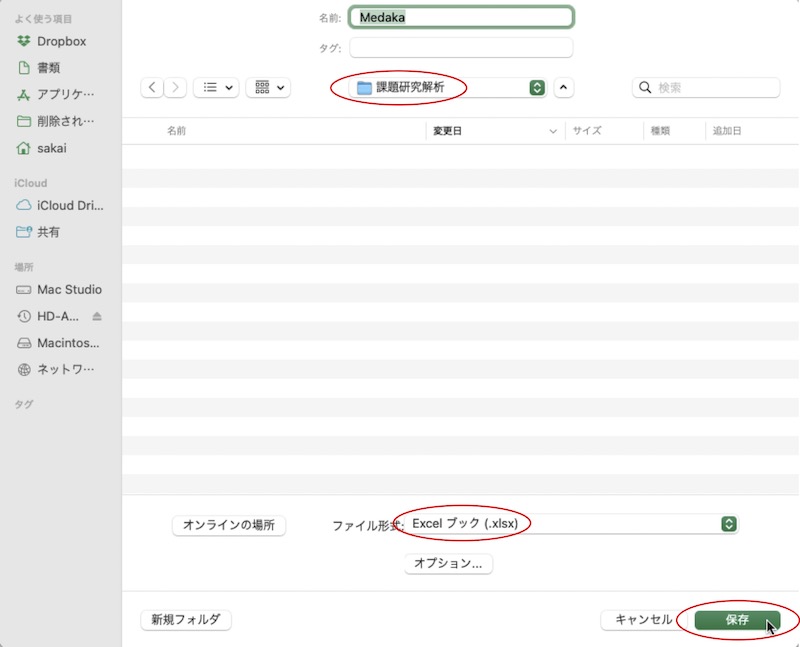
ファイル形式を、「Excelブック(.xlsx)」というExcel標準のものにして保存します。保存先は、手順1で作った解析用フォルダにします(この例では「課題研究解析」)。このファイルは、データを付け加えたり修正したりする場合に使います。バックアップ代わりにもなります。
3. Excelで作った解析用ファイルのcsv形式での保存
Rで読み込むためには、csvという形式でファイルを保存する必要があります。
上記の、Excelで作った解析用ファイルを開き、Excelのメニューの「ファイル」から「名前を付けて保存」を選択して下さい。
画面13
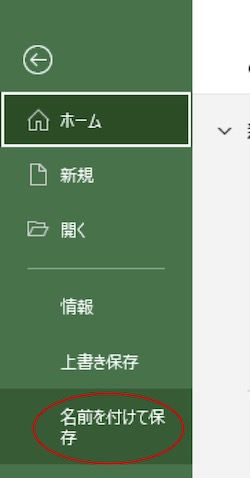
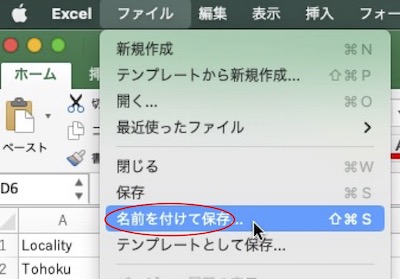
ファイルの形式を「CSV(コンマ区切り)(.csv)」にして保存します。「CSV UTF-8(コンマ区切り)(.csv)」という似た名称の形式もありますが、こちらは使わない方が無難です。
ファイル名は半角の英数字のみにして下さい。ファイル名を、元となっているExcelファイル(Excelブック(標準のファイル形式)として保存したもの)と同じにするとむしろわかりやすいです。つまり、拡張子「.csv」「.xlsx」より前の部分を同じにしてしまいます。この例では「Medaka」というファイル名にします。拡張子「.csv」「.xlsx」が異なるので元ファイルと区別がつきます。
保存先は、手順1で作った解析用フォルダにします(この例では「課題研究解析」)。
画面14
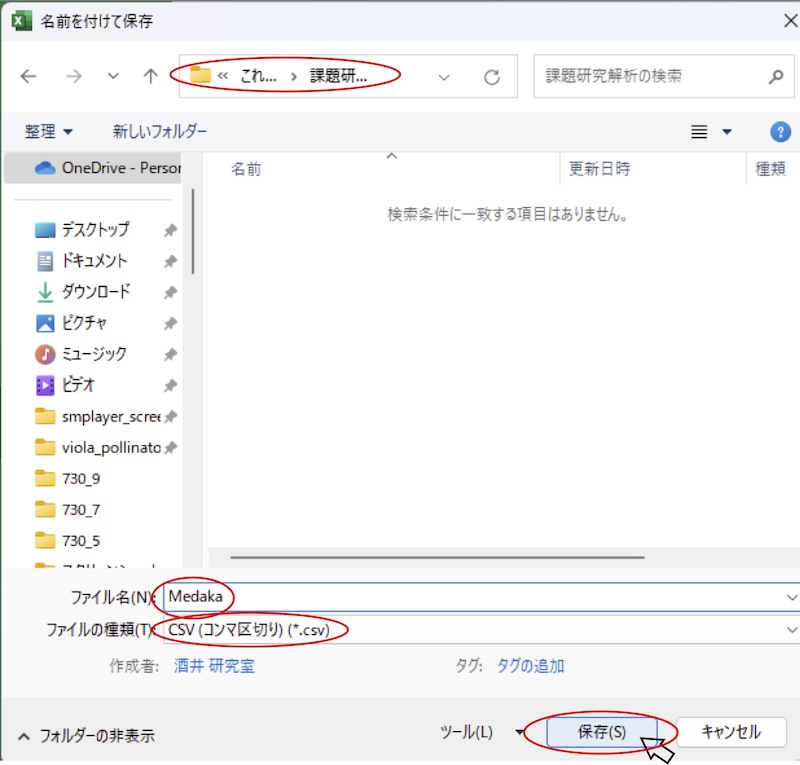
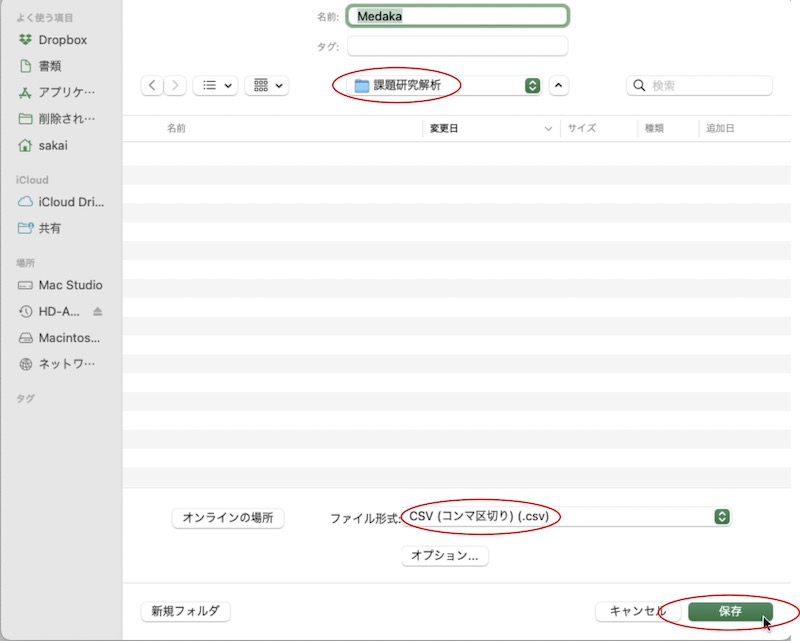
この形式で保存しようとすると、Excelが警告文を出すかもしれません。しかし構わずに保存して下さい。
保存したファイルを見て、拡張子「.csv」がファイル名に付いていることを確認して下さい。この例では、「Medaka.csv」になっているはずです。「.csv」がなくただの「Medaka」になっていたら、「.csv」を自分で書き足して下さい。
4. Excelで作った解析用ファイルのRへの読み込み
いよいよ、解析用のcsvファイルをRに読み込みます。RStudioを立ち上げて下さい(起動方法はこちらを参照)。
4.1. 作業ディレクトリの指定
まず始めに、作業ディレクトリの指定ということを行います。Rが、ファイルを読み込んだりする場所の指定です。この指定は、RStudioを立ち上げるたびに行う必要があります。
Rstudioのメニューの「Session」から「Set Working Directory」を選び、さらに「Chose Directory」と選んで下さい。
画面15
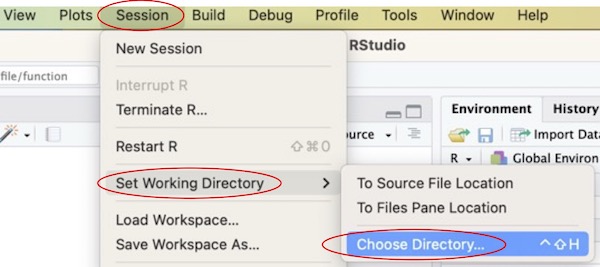
そして、手順1で作った解析用フォルダを作業ディレクトリに指定します。
画面16
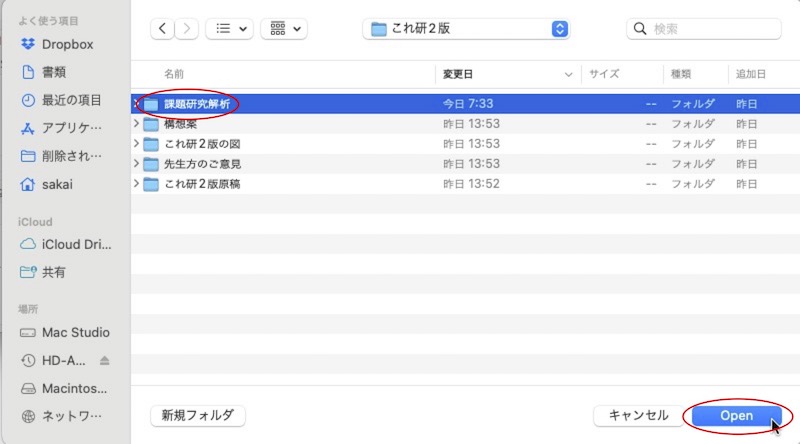
この例では、「課題研究解析」というフォルダを作業ディレクトリに指定しています。「Open」をクリックして指定します。
正しく指定されているか確認しましょう。RStudioの命令文を書き込む部分にgetwd()と書き、この命令文を実行します(実行方法はこちらを参照)。指定されている作業ディレクトリ(作業フォルダ名と、パソコン内でのその位置)が表示されます。
画面17
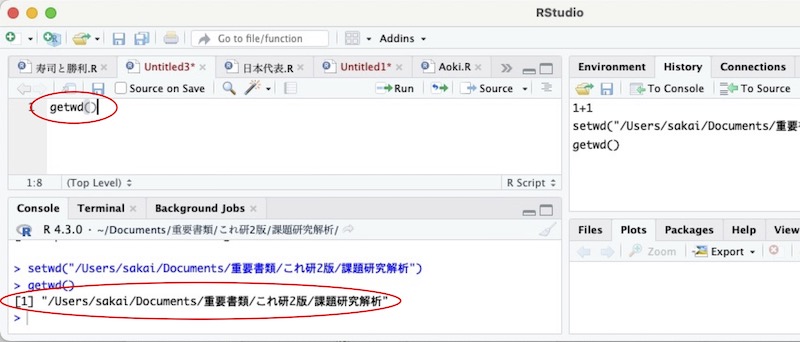
違っていたら上記手順をやり直しましょう。
作業ディレクトリの表示getwd()を実行して、指定した作業ディレクトリのパソコン内での位置がわかったら、setwd()を使った命令文を書いてしまうと便利です。作業ディレクトリの位置(画面17では、"/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析")をそのままコピーして、setwd()の()内に入れます。位置を""で囲むのを忘れないようにして下さい。
画面18
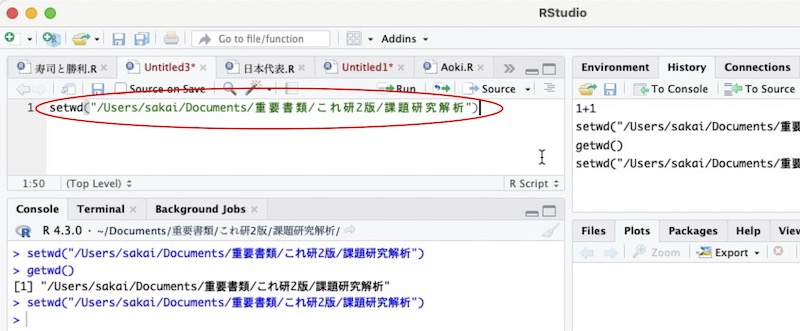
これを、命令文ファイルの先頭に書きます。そして、最初にこれを実行します。そうすると作業ディレクトリが指定されます。Rstudioのメニューバーから選んで指定するよりも楽です。
作業ディレクトリの指定4.2. 解析用ファイルのRへの読み込み
解析用のcsvファイルをRに読み込みます。Rでは、データフレームというもの(行列のようなもの)にデータを格納します。格納の命令文は以下の通りです。
格納先のデータフレーム名 <- read.csv("FileName.csv")
# FileName.csvを読み込んでデータフレームに格納します。
# 「<-」は、「<」と「-」の組合せです。ファイル名を""で囲みます。拡張子「.csv」も忘れずに書きます。
# 実行例
d <- read.csv("Medaka.csv")
# Medaka.csvを読み込んでデータフレームdに格納します。
# データフレームの名称(この例ではd)はお好みのものでよいです。
たとえば、「Medaka.csv」というファイルのデータを、dという名称のデータフレームに格納するとします。
画面19
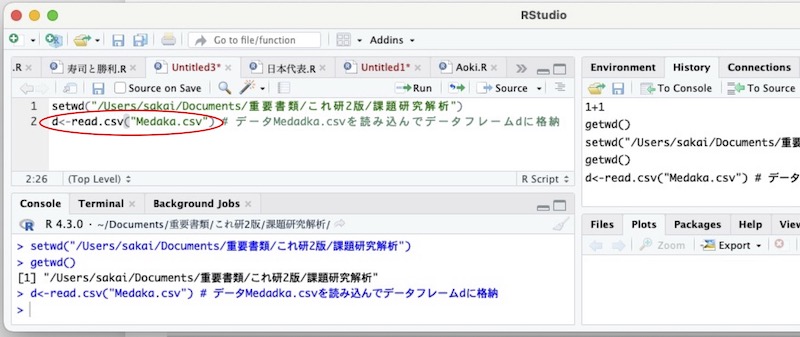
「d<-read.csv("Medaka.csv")」という命令文を実行しました。これで、データフレームdの中にMedaka.csvのデータが格納されました。
確かに格納されているのか確認してみよう。データフレームの名称dと入力して実行して下さい。ここでは、dを" "で囲んではいけません。
画面20
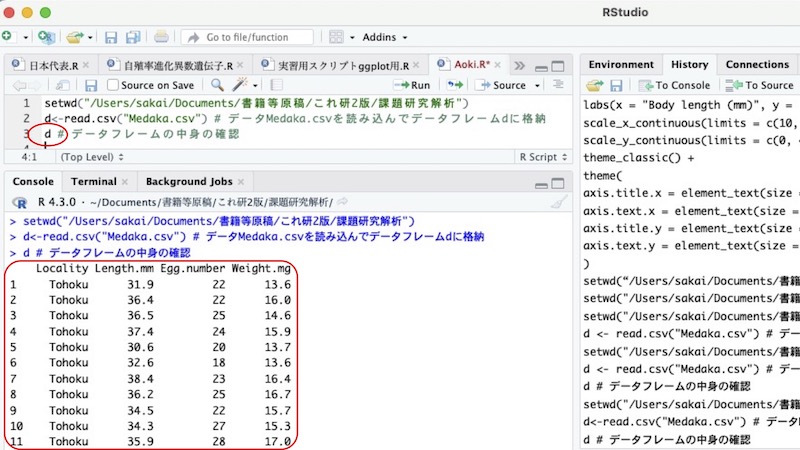
「実行結果が出る部分」に、データフレームdの中身が現れました。
読み込みがうまくいかない場合は以下の3点を確認してみて下さい。
4.3. データの並び順の指定
Medaka.csvファイルは、Localityに入っている地域名を使ってどこのメダカなのかを識別しています。同様にほとんどの場合、データのどれかを使って、何についてのデータなのかを識別します。そしてたとえば、Tohoku, Kanto, Kansai, Kyushu間で体長を比較する図を描いたりします。Rはこの場合、「Kansai, Kanto, Kyushu, Tohoku」とアルファベット順に図を並べます。しかし、図の並び順を指定したい場合もあるでしょう。「Tohoku, Kanto, Kansai, Kyushu」と北から順にというようにです。その場合は、以下のようにしてデータの並び順を指定します。
データフレーム名$データ列名 <- factor(データフレーム名$データ列名, levels=c("data1", "data2", "data3"))
# 指定したデータ列に、data1, data2, data3というデータ名称が入っているとします。
# データの並び順をdata1, data2, data3にします。並べる物が文字(Tohoku, Kantoなど)の場合は"Tohoku", "Kanto"と""で囲み、数値(25, 30など)の場合は囲んでも囲わなくてもよいです。
# データフレーム名$データ列名を上書きするために、データフレーム名$データ列名に再格納します。
# この命令を実行しないと数値順・アルファベット順に並びます。
# 「データフレーム名$データ列名」は、そのデータフレームに入っている特定のデータ列を指定する方法です。
データフレームの中の特定のデータ列の指定方法# 実行例
d$Locality <- factor(d$Locality, levels=c("Tohoku", "Kanto", "Kansai", "Kyushu"))
# データフレームdに以下のファイルを格納しました。データ列Localityに、Tohoku, Kanto, Kansai, Kyushuという地域名が入っています。
# 地域の並び順を指定します。そのために、d$Localityとして、データフレームdのデータ列Localityを指定します。
# データの並び順をTohoku, Kanto, Kansai, Kyushuにします。名称を""で囲みます。
# d$Localityの中身を上書きするためにd$Localityに再格納します。
「d$Locality」で、データフレームdの中のデータ列Localityを指定します。Localityには、Tohoku, Kanto, Kansai, Kyushuの4つの地域が入っています。levels=c()の中に並べたい順番に書きます。名称を" "で囲んで下さい。そして、d$Localityの中身を上書きするためにd$Localityに再格納します。
データの並びがアルファベット順で良いのなら、この命令文を実行する必要はありません。