これから研究を始める高校生と指導教員のために 第2版
探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方
(これ研)
副読文書
******* 命令文集 *******

本副読文書で使っているRの命令文を集めました。
Rを使うための基本的な命令文
setwd("作業ディレクトリ名")
# 作業ディレクトリ(作業フォルダ名と、パソコン内でのその位置)を指定します。作業ディレクトリ名を""で囲みます。
# 命令文ファイルの先頭に書き、最初にこれを実行します。
# 実行例
setwd("/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析")
# 「/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析」を作業ディレクトリに指定します。「課題研究解析」が作業フォルダで、その前の部分が作業フォルダの位置です。
getwd()
# 指定されている作業ディレクトリ(作業フォルダ名と、パソコン内でのその位置)を表示します。()内は空白のままこの命令文を実行して下さい。
# 実行例
getwd()
"/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析"
# 作業ディレクトリ「/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析」が表示されます。「課題研究解析」が作業フォルダで、その前の部分が作業フォルダの位置です。
install.packages("パッケージ名")
# Rに組み込まれていないパッケージ(tidyverseなど、色々な関数を集めたもの)をインストールします。これを実行しないとそのパッケージを使うことができません。一度だけインストールすればよいです。
# パッケージ名を""で囲みます。
# 実行例
install.packages("tidyverse")
# パッケージtidyverseをインストールします。
library(パッケージ名)
# インストール済みのパッケージ(tidyverseなど、色々な関数を集めたもの)を使うためにRに読み込みます。インストールした上でこの命令文を実行する必要があります。Rを起動する度に実行します。
# パッケージ名を""で囲みません。
# 実行例
library(tidyverse)
# パッケージtidyverseをRに読み込みます。
格納先のデータフレーム名 <- read.csv("FileName.csv")
# FileName.csvを読み込んでデータフレームに格納します。
# 「<-」は、「<」と「-」の組合せです。ファイル名を""で囲みます。拡張子「.csv」も忘れずに書きます。
# 実行例
d <- read.csv("Medaka.csv")
# Medaka.csvを読み込んでデータフレームdに格納します。
データの扱いの命令文
データフレーム名$データ列名
# データフレーム名を書き、$を挟んで、指定したいデータ列名を書きます。
# 実行例
d$Angle.degree
d$Flying.distance.m
# データフレームdに入っているデータ列Angle.degree, flying.distance.mを指定します。
データフレーム名$データ列名 <- factor(データフレーム名$データ列名, levels=c("data1", "data2", "data3"))
# 指定したデータ列に、data1, data2, data3というデータ名称が入っているとします。
# データの並び順をdata1, data2, data3にします。並べる物が文字(Tohoku, Kantoなど)の場合は"Tohoku", "Kanto"と""で囲み、数値(25, 30など)の場合は囲んでも囲わなくてもよいです。
# データフレーム名$データ列名を上書きするために、データフレーム名$データ列名に再格納します。上書きするので、「データフレーム名$データ列名」を2つとも同じものにします。
# この命令を実行しないと数値順・アルファベット順に並びます。
# 「データフレーム名$データ列名」は、そのデータフレームに入っている特定のデータ列を指定する方法です。
# 実行例
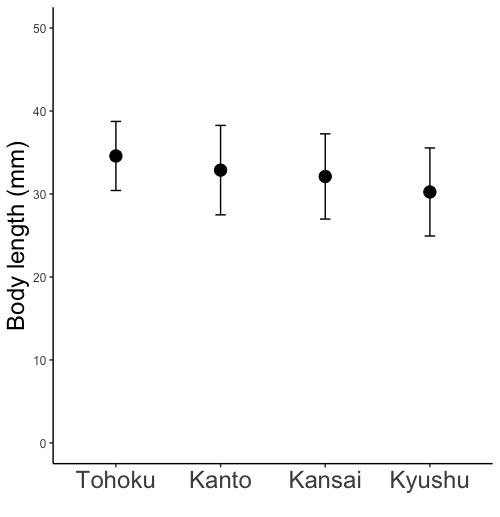
d$Locality <- factor(d$Locality, levels=c("Tohoku", "Kanto", "Kansai", "Kyushu"))
# データフレームdのデータ列Locality(d$Locality)に、Tohoku, Kanto, Kansai, Kyushuという地域名が入っています。
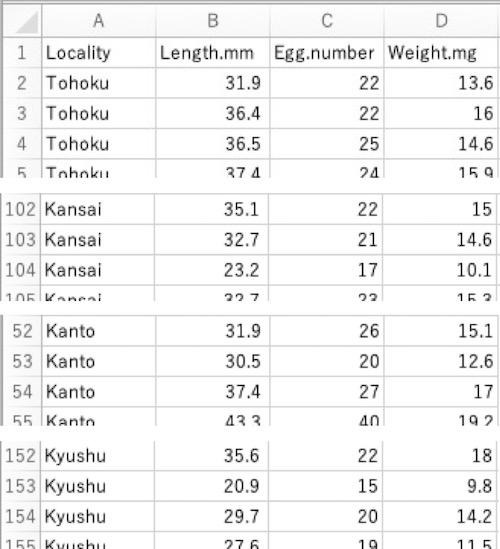
# 地域の並び順を指定します。そのために、d$Localityとして、データフレームdのデータ列Localityを指定します。
# データの並び順をTohoku, Kanto, Kansai, Kyushuにします。名称を""で囲みます。
# d$Localityの中身を上書きするためにd$Localityに再格納します。
filter(データフレーム名, 取り出す対象の条件式)
# データフレームから、「取り出す対象の条件式」に一致するデータを取り出します。
# 「取り出す対象の条件式」の中で以下を使うことができます。
# ==;一致する。=を2つ繋げ==です。
# |;orです。どれかの条件を満たすものを取り出します。
# &;andです。それらの条件を同時に満たすものを取り出します。
# 「取り出す対象の条件式」で指定するデータが文字の場合は""で必ず囲み、数値の場合は、囲っても囲わなくてもよいです。
# tidyverseをRに読み込んでおかないとfilterを使うことができません。tidyverseをインストールしていない場合は、RStudioでinstall.packages("tidyverse")を実行してインストールして下さい。インストールしたらtidyverseを読み込む必要があります。RStudioでlibrary(tidyverse)を実行して下さい。この読み込みは、Rstudioを起動するたびに行う必要があります(インストールは一度だけでよいです)。
# 実行例
# データフレームdのデータ列Localityに、Tohoku, Kanto, Kansai, Kyushuという地域名が入っています。データ列Length.mm, Egg.number, Weight.mgにデータが入っています。
filter(d, Locality == "Tohoku")
# Tohokuのデータを取り出します。
filter(d, Locality == "Tohoku" | Locality == "Kanto")
# TohokuとKantoのデータを取り出します。
filter(d, Locality == "Tohoku" & Length.mm >= 30)
# Tohokuのメダカで体長(Length.mm)が30 mm以上のデータを取り出します。
filter(d, Length.mm < 35 & Length.mm >= 30)
# 体長が30 mm以上35mm未満のデータを取り出します。
filter(d, Length.mm < 35 & Egg.number >= 20)
# 体長が35mm未満で産卵数(Egg.number)が20以上のデータを取り出します。
データフレーム名 <- c(データ1, データ2, データ3)
# csvファイルとして読み込んだデータではなく、Rの中で自分でデータを書いて格納する方法です。
# データ1, データ2, データ3,...という個々のデータをデータフレームに格納します。たとえば、Tohoku, Kanto, Kansaiといった文字データや、33.4, 32.9, 30.6などといった数値データを格納します。データをいくつでも格納できます。
# データが文字の場合は""で囲み、数値の場合は囲みません。
# 実行例
x <- c("coffee","green.tea","black.tea")
# coffee, green.tea, black.teaという名称をデータフレームxに格納します。名称なので""で囲みます。
x <- c(1, 2, 3, 4, 5)
# 1, 2, 3, 4, 5という数値をデータフレームxに格納します。数値なので""で囲みません。
データフレーム名 <- data.frame(データA, データB, データC)
# データA, データB, データC,...それぞれが複数のデータからなっています。データA, データB, データC,...を統合して新しいデータフレームを作成します。いくつでも統合できます。
# 統合する各データ(データA, データB, データC,...)のデータ数が同じである必要があります。
データAの中身;A, B, C, DデータBの中身;1, 2, 3, 4
データCの中身;0.2, 0.5, 0.8, 1.1
というようにです。データ数が異なっていたら統合できません。
# データA, データB, データC,...それぞれの中身が、新しいデータフレームのデータ列になります。データA, データB, データC,...が各データ列の名称になります。
# 実行例
d2 <- data.frame(x, y, z)
# データx, y, zの中身が以下のようになっています。

# d2 <- data.frame(x, y, z)を実行して、統合したデータをデータフレームd2に格納します。

# x, y, zの中身それぞれが新しいデータ列になります。x, y, zが、各データ列の名称です。
データフレーム名 <- data.frame(データ列名 = "名称" または データ列名 = データ値, データA, データB, データC)
# あるデータ列(この例では先頭のデータ列)に、一律に同じものを入れることもできます。名称を入れる場合は""で囲み、数値を入れる場合は囲みません。
# 実行例
d2 <- data.frame(Voice = "Rapid", x, y, z)
# データx, y, zの中身が以下のようになっています。
# d2 <- data.frame(Voice = "Rapid", x, y, z)を実行して、統合したデータをデータフレームd2に格納します。名称なので"Rapid"と囲んでいます(数値の場合は囲みません)。

# Voiceというデータ列が加わり、その中身はすべてRapidです。x, y, zの中身それぞれも新しいデータ列になっています。
データフレーム名 <- rbind(データフレームA, データフレームB, データフレームC)
# 同じデータ列を持つ複数のデータフレーム(データフレームA, データフレームB, データフレームC,...)を連結して、データが縦に増える(行が増える) 方向に統合します。連結するデータフレームは、同じ名称のデータ列からなっている必要があります。それぞれのデータ列について、連結するデータフレームのデータを統合します。データフレームをいくつでも連結できます。
# 実行例
d2 <- rbind(x3, x4)
# データフレームx3, x4の中身が以下のようになっています。

# どちらも、Voice, Var1, Freqというデータ列からなっています。d2 <- rbind(x3, x4)を実行して、統合したデータをデータフレームd2に格納します。

cbind(データ列A, データ列B, データ列C)
# 複数のデータ列(データ列A, データ列B, データ列C,...)を連結して、データが横に増える(列が増える)方向に統合します。連結するデータ列は同じ数のデータからなる必要があります。データ数が異なっているとうまく統合できません。データ列をいくつでも統合できます。
# 実行例
cbind(d$Light, d$Dark)
# データ列d$Light, d$Darkの中身が以下のようになっています。

# cbind(d$Light, d$Dark)を実行して統合します。

reshape(元のデータフレーム名, idvar = "縦方向に並べるデータ列名", timevar = "横方向に並べるデータ列名", direction = "wide")
# データフレームの形式を変換します。"縦方向に並べるデータ列名"で指定したデータ列が縦方向に、"横方向に並べるデータ列名"で指定したデータ列が横方向に並ぶデータフレームを作ります。データ列の名称を""で囲みます。
# direction = "wide"を忘れずに描きます。
# 実行例
reshape(d, idvar = "State", timevar = "Shop", direction = "wide")
# データフレームdが以下のようになっています。
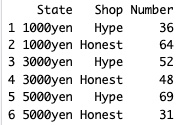
# d2 <- reshape(d, idvar = "State", timevar = "Shop", direction = "wide")を実行して、Stateが縦方向に、Shopが横方向に並ぶデータフレームを作ります。それを、データフレームd2に格納します。

データフレーム名 <- rename(データフレーム名, 変更後のデータ列名1 = 変更前のデータ列名1, 変更後のデータ列名2 = 変更前のデータ列名2)
# データ列の名称を変更します。部分的に変更する場合はrenameが便利です。いくつでも変更することができます。変更したら、同じデータフレームに再格納して上書きします。
# 実行例
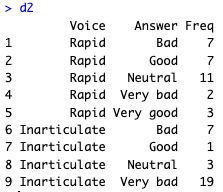
d2 <- rename(d2, Answer = Var1)
# 元々は、データフレームd2の中身が以下のようになっています。
# d2 <- rename(d2, Answer = Var1)を実行して、データ列Var1の名称をデータ列Answerに変えます。d2に再格納して上書きします。
colnames(変更するデータフレーム名) <- c("新しいデータ列名1", "新しいデータ列名2, "新しいデータ列名3")
# データフレームの列の名称を変更します。まとめて変更する場合はcolnameが便利です。名称を""で囲みます。
# そのデータフレームが持っているデータ列の数と同じ数の"新しいデータ列名"を書くようにして下さい。つまり、全データ列の分だけ"新しいデータ列名"を書きます。
# 実行例
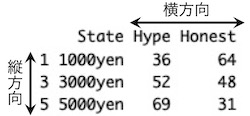
colnames(d2) <- c("State", "Hype", "Honest")
# 元々は、データフレームd2が以下のようになっています。列の名称が、State, Number.Hype, Number.Honestになっています。
# colnames(d2) <- c("State", "Hype", "Honest")を実行して、列の名称を、State, Hype, Honestに変更します。
データフレーム名$データ名 <- as.factor(データフレーム名$データ名)
# データフレーム名$データ列名で指定したデータを範疇として認識させます。
# データフレーム名$データ列名の中身を上書きするために再格納します。同じ名称のデータで上書きします。
# 実行例
d$Angle.degree <- as.factor(d$Angle.degree)
# データフレームdに入っているデータ列Angle.degreeを範疇として認識させます。上書きのために再格納します。
データ解析の命令文
tapply(データ列A, データ列B, 関数名)
tapply(データ列A, list(データ列B1, データ列B2), 関数名)
# データ列Bにデータ群の名称(群1, 群2, 群3, ...)が入っています。データ群ごとに、データ列Aのデータを関数に当てはめて計算します。
# 複数のデータ列の組合せについて計算する場合はlistを用います。たとえば、データ列B1に「群1, 群2, 群3」、データ列B2に「群A, 群B」)が入っているとします。list(データ列B1, データ列B2)で、「群1群A, 群2群A, 群3群A, 群1群B, 群2群B, 群3群B」のそれぞれを対象に計算します。
# tapplyの中で用いる場合は、関数名の後に()を付けません。
# 実行例
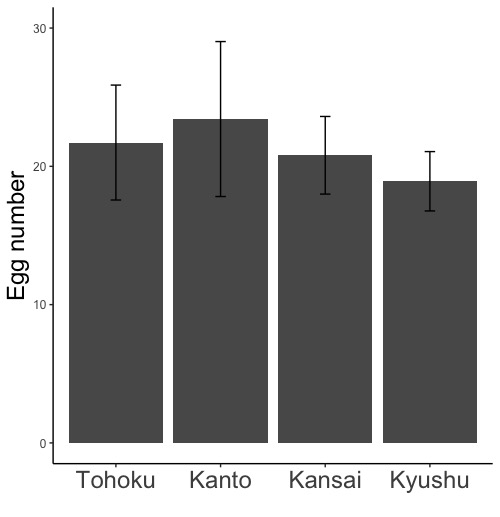
tapply(d$Length.mm, d$Locality, mean)
# メダカの体長の架空データです。データフレームdのデータ列Locality(d$Locality)に、Tohoku, Kanto, Kansai, Kyushuという地域名が入っています。データ列Length.mm(d$Length.mm)に、各地域のメダカの体長が入っています。
# 地域ごとに、体長の平均を計算します。

tapply(d$Length.mm, list(d$Temperature, d$Day), mean)
# メダカの成長実験の架空データです。データフレームdのデータ列Temperature(d$Temperature)に生育温度条件(15度・20度・25度)が、データ列Day(d$Day)に孵化からの日数(10日・30日・50日)が入っています。
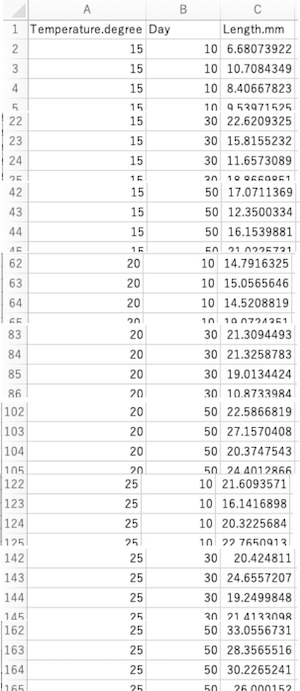
温度条件と孵化からの日数の3×3=9組ごとに、データ列d$Length.mmに入っている体長の平均を計算します。

# listの中で先に書いた方(d$Temperature)が縦(行)方向に、後に書いた方(d$Day)が横(列)方向に並びます。
関数名 <- function(x){xの関数}
# 「xの関数」部分に定義したい関数を入れます。
# 「関数名(データ)」を実行するとその関数が実行されます。
# 実行例
se <- function(x){sd(x)/sqrt(length(x))}
# 標準誤差の計算式(sd(x)/sqrt(length(x)))を定義しseに入れます。sdは、標準偏差を計算する関数、sqrtは、平方根を計算する関数、lengthは、データの数を数える関数です。()内のデータについて計算します。
# データフレームdのデータ列Flying.distance.m(d$Flying.distance.m)の中身が以下のようになっています。


quantile(データ)
# ()内のデータの中央値と四分位数を計算します。
一括して計算する場合
tapply(データ列A, データ列B, quantile)
# データ列Bにデータ群の名称(群1, 群2, 群3, ...)が入っています。データ群ごとに、データ列Aのデータの中央値と四分位数を計算します。
# tapplyの中で用いる場合は、関数名の後に()を付けません。
# 実行例
# データフレームdのデータ列Locality(d$Locality)に、Tohoku, Kanto, Kansai, Kyushuという地域名が入っています。データ列Length.mm(d$Length.mm)に体長が入っています。
quantile(d$Length.mm)
# まずは、地域を区別せずに、全地域をまとめたものの中央値と四分位数を計算してみます。

# 実行結果です。25%が第1四分位数、50%が中央値、75%が第3四分位数です。0%が最小値、100%が最大値です。
tapply(d$Length.mm, d$Locality, quantile)
# 次は、地域ごとに、体長の中央値と四分位数を計算します。

# 実行結果です。25%が第1四分位数、50%が中央値、75%が第3四分位数です。0%が最小値、100%が最大値です。
table(集計するデータ)
# 集計するデータに入っているデータを集計します。データ群ごとにデータ数を数えます。
# 実行例
table(d$Rapid)
# データフレームdのデータ列Rapid(d$Rapid)の中身が以下のようになっています。

# table(d$Rapid)で各回答数を集計します。

prop.table(table(集計するデータ))
集計するデータに入っている、各データ群の割合を計算します。
# 実行例
prop.table(table(d$Rapid))
# データフレームdのデータ列Rapid(d$Rapid)の中身が以下のようになっています。
# prop.table(table(d$Rapid))で各回答の割合を計算します。

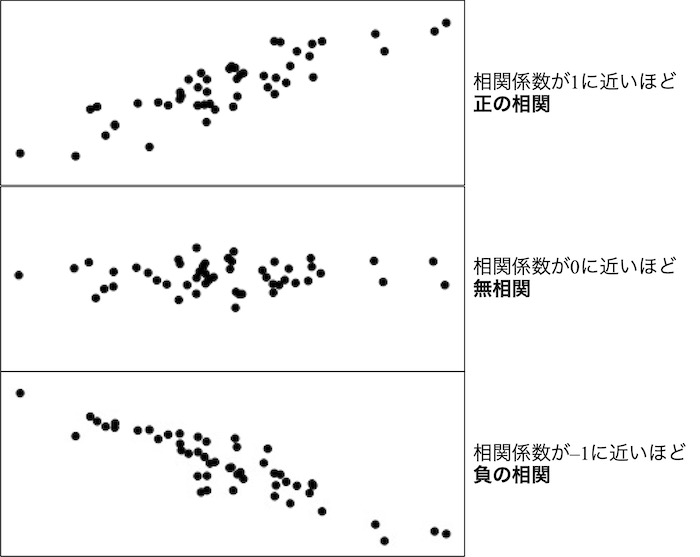
cor(データ列A, データ列B)
# データ列Aとデータ列Bの相関係数を計算します。
# 相関係数は、-1から1までの値を取ります。1に近いほど正の相関が強く、0に近いほど無相関で、-1に近いほど負の相関が強いです。
# 実行例
cor(d$Length.mm, d$Weight.mg)
# データフレームdのデータ列Length.mm(d$Length.mm)にメダカの体長が, データ列Weight.mg(d$Weight.mg)に体重が入っています。
# cor(d$Length.mm, d$Weight.mg)を実行して両者の相関係数を計算します。ここでは、地域を区別せずに全地域のものをまとめて計算しています。

作図の命令文
ggplot(データフレーム名, aes(x = 作図するデータ列名, color = 棒の枠線の色分けに用いるデータ列名, fill = 棒の内部の色分けに用いるデータ列名))
# 作図に用いるデータフレームと、作図するデータ列をx軸(横軸)として指定します。xは小文字です。
# 複数のデータ群について図を描き、データ群ごとに色分けをしたい場合は、棒の枠線の色分けに用いるデータ列をcolorで、棒の内部の色分けに用いるデータ列をfillで指定します。color, fillで指定したデータ列に記述されている対象ごとに色分けをします。通常は、color, fillに同じデータ列を指定します。color, fillを指定しないと全対象が同じ色で描かれます。
# 全地域のヒストグラムを一枚の図に描く場合は必ず色分けをして下さい。
# 実行例
# データフレームdのデータ列Localityに、Tohoku, Kanto, Kansai, Kyushuという地域名が入っています。データ列Length.mmに体長が入っています。
ggplot(d, aes(x = Length.mm, color = Locality, fill = Locality))
# 体長(Length.mm)のヒストグラムを描きます。color = Locality, fill = Localityと指定して地域(Locality)で色分けをします。
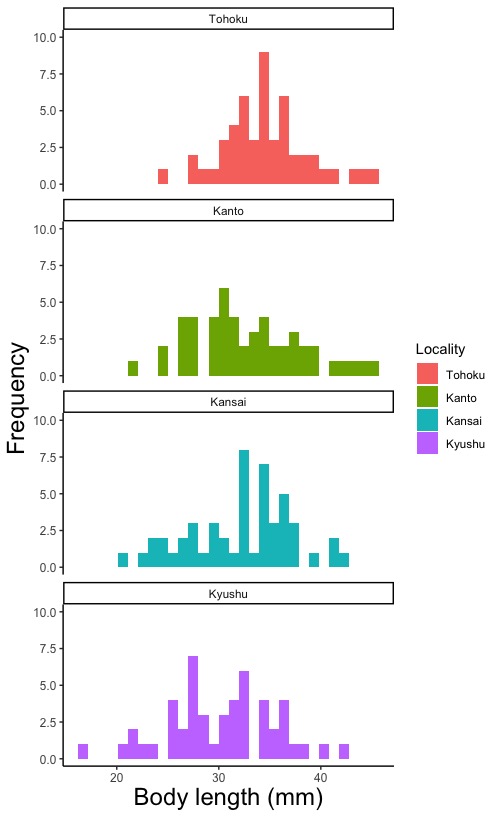
# 各地域のヒストグラムを別々の図に描く場合(別々の図に描く方法は複数の図を並べて描くを参照)
# 全地域のヒストグラムを一枚の図に描く場合(一枚の図に描く方法は複数の図を並べて描くを参照)
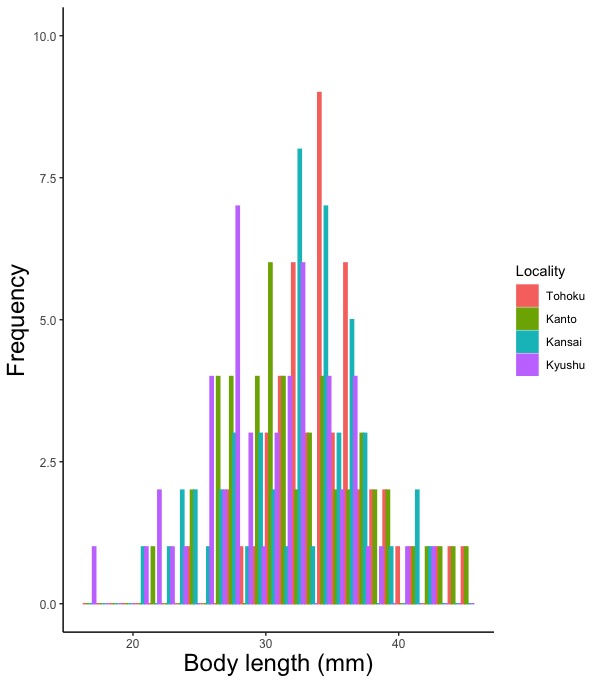
ggplot(d, aes(x = Length.mm))
# 体長(Length.mm)のヒストグラムを描きます。color, fillを指定せず色分けをしません。
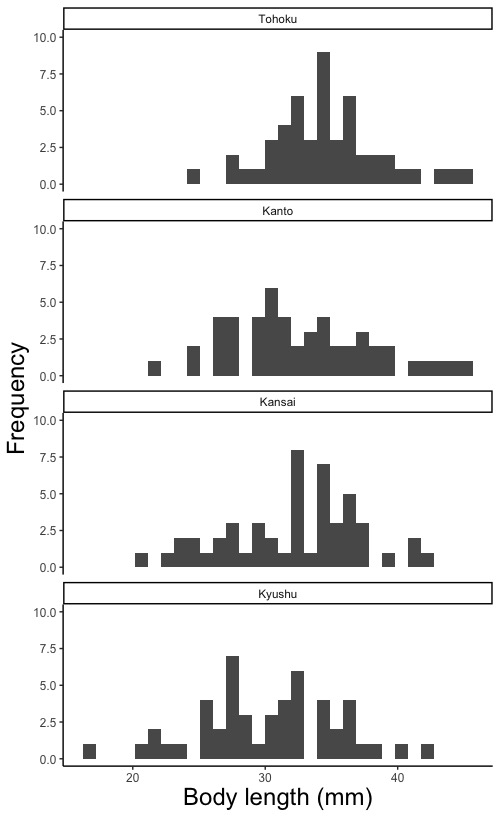
# 個々のヒストグラムを並べて描く場合
geom_histogram(binwidth = 個々の棒の横幅, color = "枠線の色の英語名", fill = "内部の色の英語名")
# 複数の対象のヒストグラムを一枚の図に描く場合
geom_histogram(binwidth = 個々の棒の横幅, position = "描き方")
# ヒストグラムを指定します。
# binwidth = で、個々の棒の横幅を指定します。x軸(横軸)の値を区切る幅の設定です。
# 個々のヒストグラムを並べて描く場合
# color =で棒の枠線の色を、fill =で内部の色を指定します。"red", "blue", "white"などです。英語名を""で囲みます。これらを指定しないと自動で描きます。ヒストグラムにおける、作図に用いるデータフレームとデータの指定において色分けを指定した場合は、geom_histogramで色指定をしないで下さい。指定すると、色が上描きされておかしなことになります。
# 個々のヒストグラムを並べて描く方法は複数の図を並べて描くを参照して下さい。
# 複数の対象のヒストグラムを一枚の図に描く場合
# position = で各対象の棒の並べ方を指定します。
# position = "dodge";各対象の同じデータ値の棒(たとえば体長2.0 - 2.2 mmの棒)を、重ならないようにずらして横に並べます。通常は"dodge"を指定します。
# position = "identity";各対象の同じデータ値の棒を、ずらさずに同じ位置に重ねて描きます。
# position = "fill" ;各データ値における各対象の数を相対値で描きます。
# ヒストグラムにおける、作図に用いるデータフレームとデータの指定で色分けの指定を必ずして下さい。そのかわり、geom_histogramでの色指定はしません。
# 複数の対象のヒストグラムを一枚の図に描く方法は複数の図を並べて描くを参照して下さい。
# 実行例
# 複数の対象のヒストグラムを一枚の図に描く場合
geom_histogram(binwidth = 2)
# 個々の横棒の幅を2(2 mm刻み)に指定します。

geom_histogram()
# 横棒の幅を指定せず、自動で描かせます。
geom_histogram(color ="red", fill = "blue")
# 棒の枠線の色を赤に、内部の色を青にします。

# 複数の対象のヒストグラムを一枚の図に描く場合
# ヒストグラムにおける、作図に用いるデータフレームとデータの指定で色分けを指定して下さい。
# 命令文facet_wrap()を実行しないで下さい。
geom_histogram(position = "dodge")
# 各対象の同じデータ値の棒(たとえば体長2.0 - 2.2 mmの棒)を、重ならないようにずらして横に並べます。
geom_histogram(position = "identity")
# 各対象の同じデータ値の棒を、ずらさずに同じ位置に重ねて描きます。
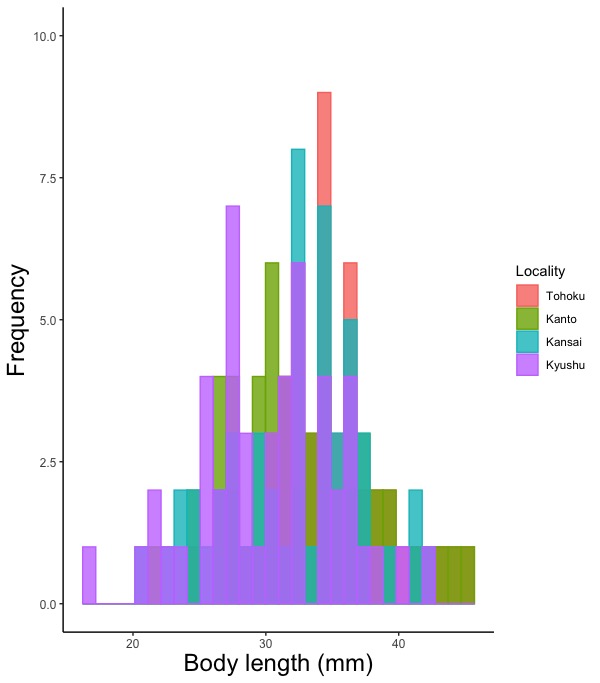
geom_histogram(position = "fill")
# 各データ値における各対象の数を相対値で描きます。
ggplot(データフレーム名, aes(x = データ群の名称が入ったデータ列名, y = y軸に描くデータ列名, color = 線の色分けに用いるデータ列名, fill = 箱の内部の色分けに用いるデータ列名))
# 作図に用いるデータフレームを指定します。
# データ群の名称(Tohoku, Kanto, Kansai, Kyushuなど)が入ったデータ列をx軸(横軸)に指定します。データ群ごとにx軸(横軸)に並べて描きます。xは小文字です。
# 描く数値が入ったデータ列をy軸に指定します。yは小文字です。
# データ群ごとに色分けをしたい場合は、線の色分けに用いるデータ列をcolorで、箱の内部の色分けに用いるデータ列をfillで指定します。color, fillで指定したデータ列に記述されている対象ごとに色分けをします。通常は、color, fillに同じデータ列を指定します。color, fillを指定しないと全対象が同じ色で描かれます。
# 実行例
# データフレームdのデータ列Localityに、Tohoku, Kanto, Kansai, Kyushuという地域名が入っています。データ列Length.mmに体長が入っています。
ggplot(d, aes(x = Locality, y = Length.mm, color = Locality))
# 体長(Length.mm)の箱ひげ図を描きます。color = Localityと指定して、線のみを地域(Locality)で色分けします。

ggplot(d, aes(x = Locality, y = Length.mm, color = Locality, fill = Locality)) +
geom_boxplot(color = "black")
# color = Locality, fill = Localityと指定して、線と箱の内部を地域(Locality)で色分けします。この命令文だけだと中央値(箱の内部の横線)も同じ色になり埋もれてしまうので、geom_boxplot(color = "black")と指定して(箱ひげ図の指定を参照)中央値の横線を黒にします。

ggplot(d, aes(x = Locality, y = Length.mm))
# color, fillを指定せず色分けをしません。
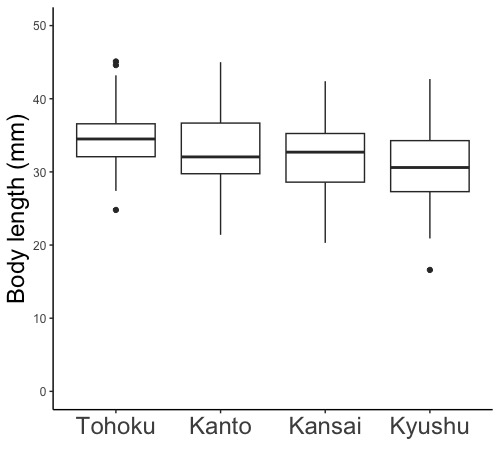
geom_boxplot(width = 箱の横幅, linewidth = 箱の枠線の太さ, color = "箱の枠線の色の英語名", fill = "箱の内部の色の英語名")
# 箱ひげ図を指定します。
# width =で、箱の横幅を指定します。0より大で1以下の数値を指定して下さい。指定しないと自動で描きます。
# linewidth =で、箱の枠線の太さを指定します。指定しないと自動で描きます。
# color =で箱の枠線の色を、fill =で内部の色を指定します。"red", "blue", "white"などです。英語名を""で囲みます。これらを指定しないと黒で描きます。箱ひげ図における、作図に用いるデータフレームとデータの指定において色分けを指定した場合は、geom_boxplotで色指定をしないで下さい。指定すると、色が上描きされておかしなことになります。
# 実行例
geom_boxplot(width = 1)
# 箱の両側に空白を入れません。
geom_boxplot(width = 0.5)
# 箱の両側に25%ずつの空白を入れます。

geom_boxplot(linewidth = 1)
# 枠線の太さを1にします。
geom_boxplot(linewidth = 3)
# 枠線の太さを3にします。
geom_boxplot(color = "red", fill = "black")
# 棒の枠線の色を赤に、内部の色を黒にします。
ggplot(データフレーム名, aes(x = x軸とするデータ列名, y = y軸とするデータ列名, color = 点の色分けに用いるデータ列名, shape = 点(記号)の形の描き分けに用いるデータ列名))
# 作図に用いるデータフレームと、x軸(横軸)・y軸(縦軸)とするデータ列を指定します。"x =", "y ="のx, yは小文字です。
# 複数のデータ群について散布図を描き、データ群ごとに色分けをしたい場合は、色分けに用いるデータ列をcolorで指定します。colorを指定しないと全対象が同じ色で描かれます。
# 複数のデータ群について散布図を描き、データ群ごとに、違う形の点(記号)で描きたい場合は、描き分けに用いるデータ列をshapeで指定します。shapeを指定しないと全対象が同じ形の記号で描かれます。
# 複数の対象の散布図・点グラフを一枚の図に描く場合は必ず、色や形を描き分けて下さい。
scale_colour_manual(values = c("色の英語名", "色の英語名", "色の英語名"))
scale_shape_manual(values = c(形の番号, 形の番号, 形の番号))
# 点(記号)の色と形を自分で指定する場合です。色と形の両方を指定することも、どちらかのみを指定することもできます。ggplotで、color =, shape =による色分け・描き分けを指定した上で、+で繋げて実行します。色分け・描き分けの種類の数だけ指定して下さい。色の英語は""で囲み、形の番号は囲みません。
# 形の番号 = 0;□ 1;○ 2;△ 5;◇ 6;▽ 15;■ 17;▲ 18;◆ 19;●
# 実行例
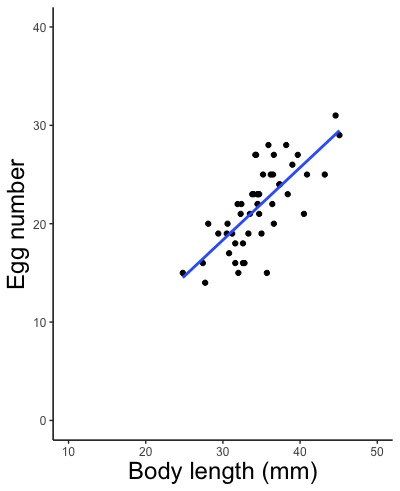
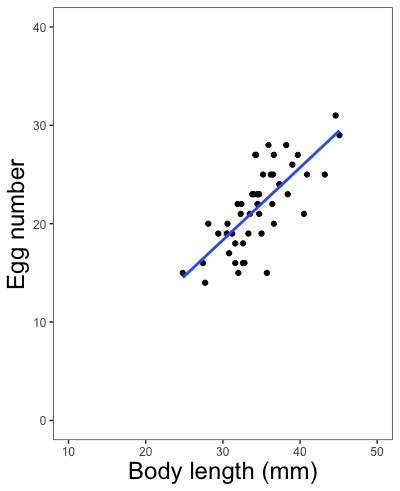
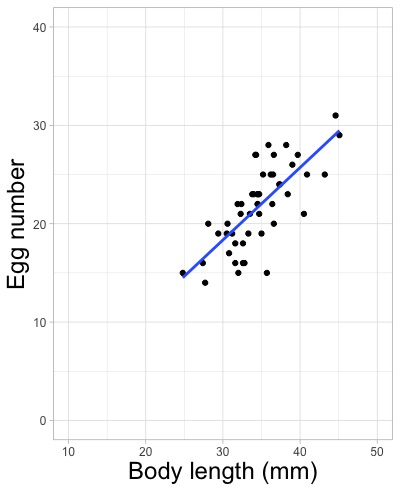
ggplot(d, aes(x = Length.mm, y = Egg.number, color = Locality))
# color = Localityと指定して地域(Locality)で色分けをします。
# 個々の散布図・点グラフを並べて描く場合(複数の図を並べて描く方法は複数の図を並べて描くを参照)
# 複数の対象の散布図・点グラフを一枚の図に描く場合(一枚の図に描く方法は複数の図を並べて描くを参照)
ggplot(d, aes(x = Length.mm, y = Egg.number))
# colorを指定せず色分けをしません。

ggplot(d, aes(x = Length.mm, y = Egg.number, shape = Locality))
# shape = Localityと指定して、地域(Locality)ごとに異なる形の記号で描きます。

ggplot(d, aes(x = Length.mm, y = Egg.number, shape = color, shape = Locality))
# shape = color, shape = Localityと同時に指定して、色と形の両方を変えて描くこともできます。
ggplot(d, aes(x = Length.mm, y = Egg.number, shape = color, shape = Locality)) +
scale_colour_manual(values = c("red", "blue", "red", "blue")) +
scale_shape_manual(values = c(19, 19, 17, 17))
# 点(記号)の色と形を自分で指定します。赤丸・青丸・赤三角・青三角にします。
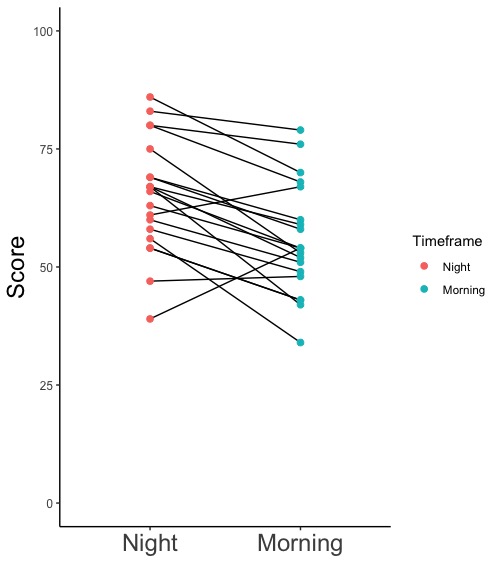
ggplot(データフレーム名, aes(x = データ群の名称が入ったデータ列名, y = y軸に描くデータ列名, group = データの対応付けに用いるデータ列名, color = 点の色分けに用いるデータ列名)
# 作図に用いるデータフレームを指定します。
# データ群の名称(Night, Morningなど)が入ったデータ列をx軸(横軸)に指定します。データ群ごとにx軸(横軸)に並べて描きます。xは小文字です。
# 描く数値が入ったデータ列をy軸に指定します。yは小文字です。
# データに対応関係があり、対応するデータ点を線で結ぶ場合は、group =で、データの対応付けに用いるデータ列名を指定します。このデータ列のデータ値が同じものを線で結びます。データ点を線で結ばない場合はこの命令は不要です。
# データ群ごとに点を色分けをしたい場合は、データ群の名称が入ったデータ列をcolorで指定します。colorを指定しないと全対象が同じ色で描かれます。
# ここで色分けをする場合は、散布図・点グラフの指定での色分け(colorの指定)をしないで下さい。指定すると、色が上描きされておかしなことになります。
# 実行例
データに対応関係がなく、データ点を線で結ばない場合
# データフレームd2のデータ列xに地域名が、データ列yに平均体長が、データ列zに標準偏差が入っています。

ggplot(d2, aes(x = x, y = y, color = x))
# ccolor = xと指定して地域(x)で色分けをします。

ggplot(d2, aes(x = x, y = y))
# colorを指定せず色分けをしません。
データに対応関係があり、データ点を線で結ぶ場合
# データフレームdのデータ列Studentに試験を受けた生徒の番号(同じ番号が同一生徒)が、データ列Timeframeに単語記憶をした時間帯(NightかMorningか)が、Scoreに記憶成績(高いほど良い)が入っています。同じ生徒の記憶成績は対応関係にあります。
ggplot(d, aes(x = Timeframe, y = Score, group = Student, color = Timeframe))
# group = Studentとして、同じ生徒のデータ点を線で結びます。color = Timeframeと指定して記憶時間帯(Timeframe)で色分けをします。

ggplot(d, aes(x = Timeframe, y = Score, group =Student))
# group = Studentとして、同じ生徒のデータ点を線で結びます。colorを指定せず色分けをしません。
geom_point(size = 点の大きさ, color = "色の英語名", shape = 点の形)
# 点グラフを指定します。
# size =で点の大きさを指定します。指定しないと自動で描きます。
# colorで点の色を指定します。"red", "blue", "green"などです。英語名を""で囲みます。指定しないと黒で描きます。
# shape =で点(記号)の形を指定します。指定しないと自動で描きます。
# shape = 0;□ 1;○ 2;△ 5;◇ 6;▽ 15;■ 17;▲ 18;◆ 19;●
散布図または点グラフにおける、作図に用いるデータフレームとデータの指定においてcolor, shapeを指定した場合は、geom_pointでcolor, shapeを指定しないでください。指定すると、color, shapeが上描きされておかしなことになります。
# 実行例
geom_point(size = 6, shape = 1, color = "red")
# 大きさ6の中空きの○を赤で描きます。
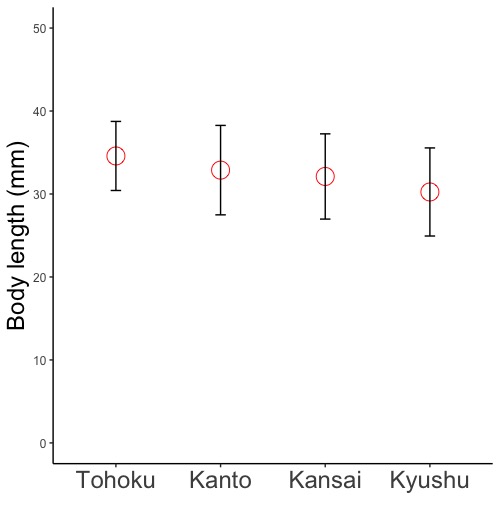
geom_point()
# 何も指定せず自動で描かせます。
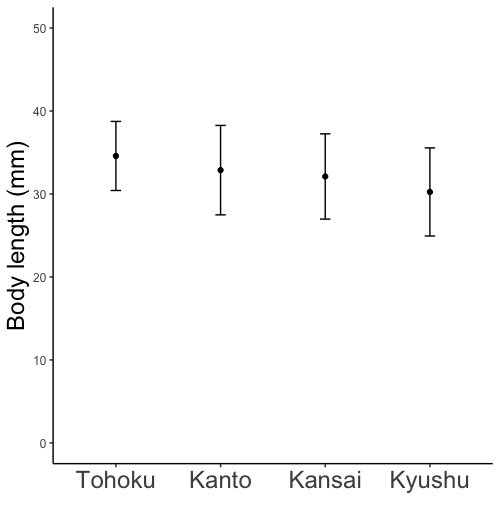
ggplot(データフレーム名, aes(x = x軸とするデータ列名, y = y軸とするデータ列名, color = 線の色分けに用いるデータ列名))
# 作図に用いるデータフレームと、x軸(横軸)・y軸(縦軸)とするデータ列を指定します。"x =", "y ="のx, yは小文字です。
# 複数のデータ群について折れ線グラフを色分けして描く場合は、色分けに用いるデータ列をcolorで指定します。
# 実行例
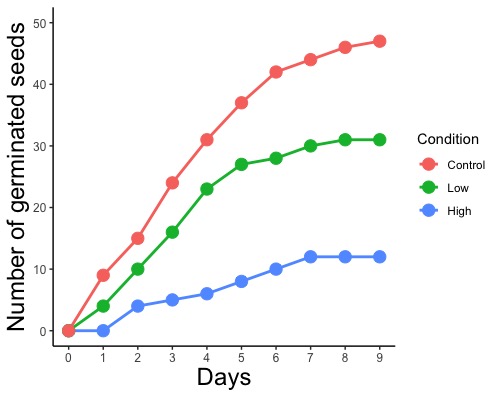
ggplot(d, aes(x = Day, y = Number, color = Condition))
# color = Conditionと指定して発芽条件(Condition)で色分けをします。
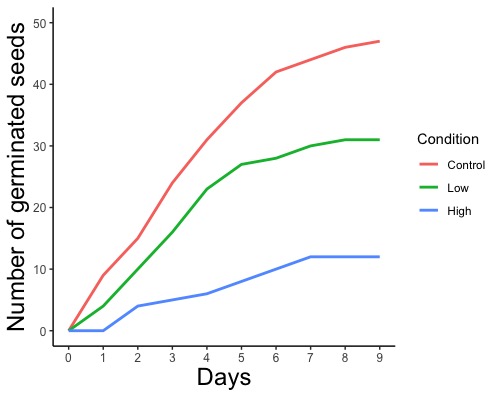
geom_line(linewidth = 線の太さ, color = "線の色の英語名", linetype = "線の種類の英語名")
# 折れ線グラフを指定します。
# linewidth =で線の太さを指定します。指定しないと自動で描きます。
# color =で線の色を指定します。"red", "blue", "green"などです。英語名を""で囲みます。指定しないと黒で描きます。点グラフにおける、作図に用いるデータフレームとデータの指定において色分けを指定すると、線の色も変わってしまいます(実行例)。これが嫌ならば、geom_lineで線の色を指定して下さい(黒とかに)。
# linetype =で線の種類を指定します。英語名を""で囲みます。指定しないと実線で描きます。
# linetype = "solid";実線 "dashed";破線 "dotted";点線
# 実行例
geom_line(linewidth = 2, color = "red", linetype = "dashed")
# 線の太さを2に、線の色を赤に、線の種類を破線にします。
geom_line()
# 何も指定せず自動で描かせます。
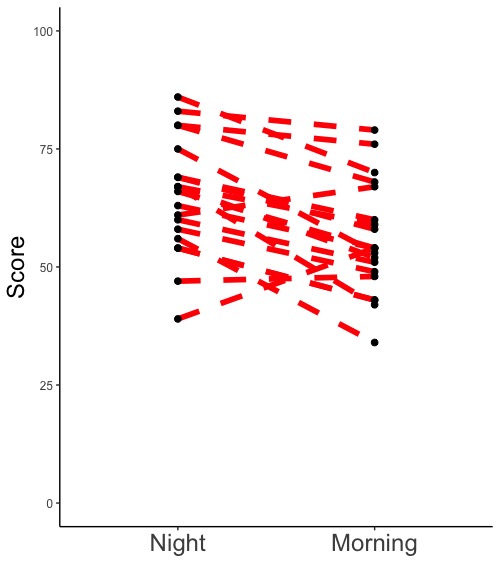
ggplot(d, aes(x = Timeframe, y = Score, group =Student, color = Timeframe)) +
geom_line(color = "black")
# 1行目の命令文で、データの種類ごとに色分けをしています(点グラフにおける、作図に用いるデータフレームとデータの指定を参照)。そうすると線の色も変わってしまうので、2行目で、線の色を黒に指定します。上の実行例と異なり黒い線で結んでいます。
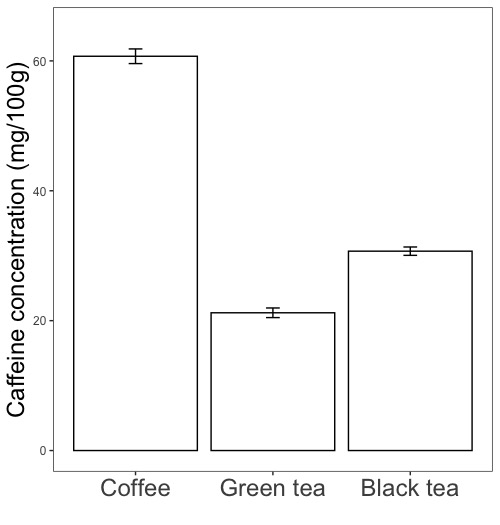
ggplot(データフレーム名, aes(x = データ群の名称が入ったデータ列名, y = y軸に描くデータ列名, color = 棒の枠線の色分けに用いるデータ列名, fill = 棒の内部の色分けに用いるデータ列名))
# 作図に用いるデータフレームを指定します。
# データ群の名称(Coffee, Green teaなど)が入ったデータ列をx軸(横軸)に指定します。データ群ごとにx軸(横軸)に並べて描きます。xは小文字です。
# 描く数値が入ったデータ列をy軸に指定します。yは小文字です。
# データ群ごとに色分けをしたい場合は、棒の枠線の色分けに用いるデータ列をcolorで、棒の内部の色分けに用いるデータ列をfillで指定します。color, fillで指定したデータ列に記述されている対象ごとに色分けをします。通常は、color, fillに同じデータ列を指定します。color, fillを指定しないと全対象が同じ色で描かれます。
# ここで色分けを指定する場合は、棒グラフの指定での色分け(fill, colorの指定)をしないで下さい。指定すると、色が上描きされておかしなことになります。
# 実行例
# データフレームdのデータ列xに飲料の種類が、データ列yに平均カフェリン量が、zに標準誤差が入っています。

ggplot(d2, aes(x = x, y = y, color = x, fill = x))
# 飲料の種類(x)ごとにカフェイン量の平均値(y)を描きます。color = x, fill = xと指定して飲料の種類(x)で色分けをします。
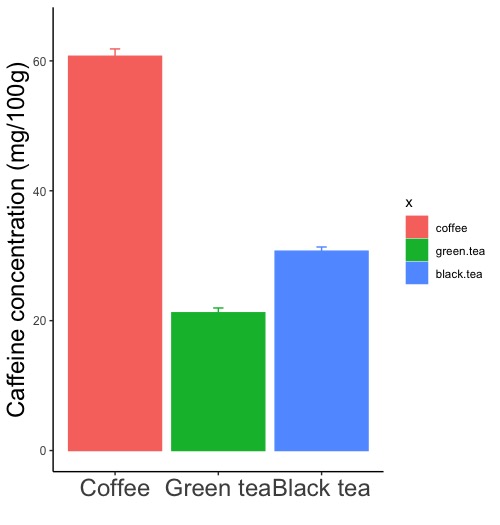
ggplot(d2, aes(x = x, y = y))
# color, fillを指定せず色分けをしません。
# 棒グラフの指定で、棒の枠線を黒に、内部を白に指定しています。
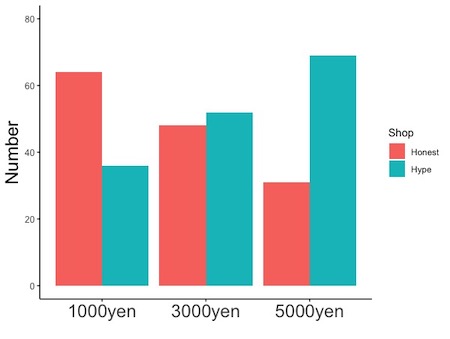
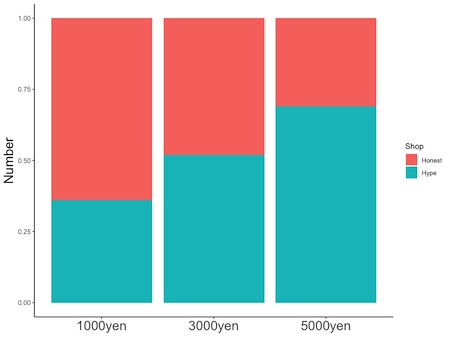
# x軸の一つの値に対して一つの棒グラフを描く場合;positionの指定不要 geom_bar(stat = "identity", width = 棒の横幅, linewidth = 棒の枠線の太さ, color = "棒の枠線の色の英語名", fill = "棒の内部の色の英語名") # x軸の一つの値に対して複数の棒グラフを描く場合;positionを指定 geom_bar(stat = "identity", width = 棒の横幅, linewidth = 棒の枠線の太さ, color = "棒の枠線の色の英語名", fill = "棒の内部の色の英語名", position = "描き方") # 棒グラフを指定します。 # x軸の一つの値に対して複数の棒グラフを描くことがあります。たとえば、誇大広告の店に行くか正直な広告の店に行くかの棒グラフを描くとします。この図では、x軸(所持金)
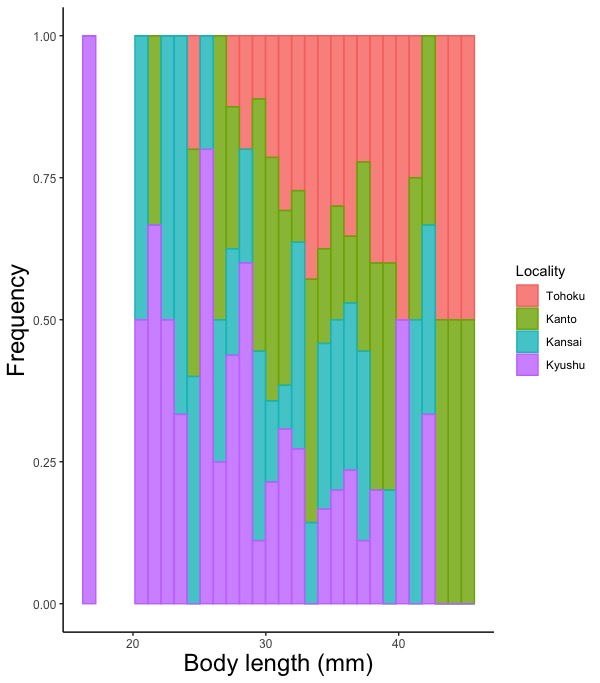
の値1000円, 2000円, 3000円それぞれについて、Honest(正直), Hype(誇大)という二つの棒グラフを描いています。このような場合は、position = で描き方を指定します。 # position = "dodge";各棒を、重ならないようにずらして横に並べます。 # x軸の一つの値に対して一つの棒グラフを描く場合はposition = の指定は不要です。 # width =で、棒の横幅を指定します。0より大で1以下の数値を指定して下さい。指定しないと自動で描きます。 # linewidth =で、棒の枠線の太さを指定します。指定しないと自動で描きます。 # color =で棒の枠線の色を、fill =で内部の色を指定します。"red", "blue", "white"などです。英語名を""で囲みます。これらを指定しないと黒で描きます。棒グラフにおける、作図に用いるデータフレームとデータの指定において色分けを指定した場合は、geom_barで色指定をしないで下さい。指定すると、色が上描きされておかしなことになります。 # stat = "identity"を忘れずに書いて下さい。 # 実行例 # x軸の一つの値に対して一つの棒グラフを描く場合;positionの指定不要 geom_bar(stat = "identity", width = 1) geom_bar(stat = "identity", width = 0.5) geom_bar(stat = "identity", linewidth = 1, color = "black", fill = "white") geom_bar(stat = "identity", color = "red", fill = "red") geom_bar(stat = "identity") # x軸の一つの値に対して複数の棒グラフを描く場合;positionを指定 # 棒グラフにおける、作図に用いるデータフレームとデータの指定で、full =を用いて、棒の内部の色分けに用いるデータ列を指定しておいて下さい。この指定をすると、x軸の一つの値に対して複数の棒グラフを描きます。 geom_bar(stat = "identity", position = "dodge") geom_bar(stat = "identity", position = "fill")
# position = "fill" ;x軸の各データ値において、各棒の値の相対値を示します。
# 棒の両側に空白を入れません。

# 棒の両側に25%ずつの空白を入れます。

# 枠線の太さを1に、棒の枠線を黒に、内部を白にします。
# 棒の枠線と内部を赤にします。
# 何も指定せず自動で描かせます。
# 各棒を、重ならないようにずらして横に並べます。
# x軸の各データ値において、各棒の値の相対値を示します。
データ列に入っている数値を用いて複数の図を描く場合
ggplot(データフレーム名, aes(x = データ群の名称が入ったデータ列名, y = 作図する数値の入ったデータ列名, fill = 帯の色分けに用いるデータ列名)) +
geom_bar(stat = "identity", position = "fill")
# ggplot
# 作図に用いるデータフレームを指定します。
# 複数のデータ群の図を描く場合は、データ群の名称が入ったデータ列名をx軸として指定します。xは小文字です。
# 作図する数値が入っているデータ列をy軸として指定します。yは小文字です。
# fill =で、帯の色分けに用いるデータ列を指定します。そのデータ列に記述されているものごとに色分けをします。
# geom_bar
# ggplotでy軸に指定したデータ列にデータの数値が入っており、その数値を作図する場合はstat = "identity"を指定します。identityを""で囲みます。
# position = "fill"と指定すると、各回答数の割合(百分率)を表示します。fillを""で囲みます。この命令文を省略してgeom_bar(stat = "identity")すると、各回答数の絶対数を表示します。円グラフに変換する場合はposition = "fill"を省略してよいです。
# 実行例
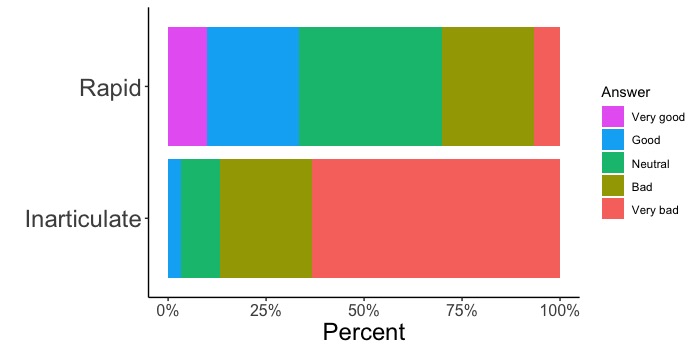
# 音声の聞き取りやすさのアンケート結果を作図しましょう。データフレームd2のデータ列Voiceに音声の種類、Answerに聴き取りやすさ、Freqにそれぞれの回答数が入っています。
ggplot(d2, aes(x = Voice, y = Freq, fill = Answer)) +
geom_bar(stat = "identity", position = "fill")
# データ列Voiceに、早口(Rapid)か発音不明瞭(Inarticulate)かが記述されています。早口と発音不明瞭それぞれの図を描きます。x = Voiceとして、描き分けに用いるデータ列にVoiceを指定します。
# データ列Freqに、Very good, Good, Neutral, Bad, Very badの各回答数が入っています。y = Freqとして、描く数値のデータ列にFreqを指定します。
# データ列Answerに、Very good, Good, Neutral, Bad, Very badという回答の名称が記述されています。回答ごとに色分けをします。fill = Answerとして、色分けに用いるデータ列にAnserを指定します。
# position = "fill"として百分率で描きます。
ggplot(d2, aes(x = Voice, y = Freq, fill = Answer)) +
geom_bar(stat = "identity")
# position = "fill"を指定せず、絶対数で描きます。
# scale_y_continuous(labels = percent)も実行しないで下さい。この命令文は百分率で軸を示すものですので、絶対数の場合に使うことができません。

データ列に入っている数値を用いて1つの図を描く場合
ggplot(データフレーム名, aes(x = "", y = 作図する数値の入ったデータ列名, fill = 帯の色分けに用いるデータ列名)) +
geom_bar(stat = "identity", position = "fill")
# ggplot
# 作図に用いるデータフレームを指定します。
# 1つの図を描く場合はx軸を指定しません。x = ""とします。xは小文字です。""の中は空です。
# 作図する数値が入っているデータ列をy軸として指定します。yは小文字です。
# fill =で、帯の色分けに用いるデータ列を指定します。そのデータ列に記述されているものごとに色分けをします。
# geom_bar
# ggplotでy軸に指定したデータ列にデータの数値が入っており、その数値を作図する場合はstat = "identity"を指定します。identityを""で囲みます。
# position = "fill"と指定すると、各回答数の割合(百分率)を表示します。fillを""で囲みます。この命令文を省略してgeom_bar(stat = "identity")すると、各回答数の絶対数を表示します。円グラフに変換する場合はposition = "fill"を省略してよいです。
# 実行例
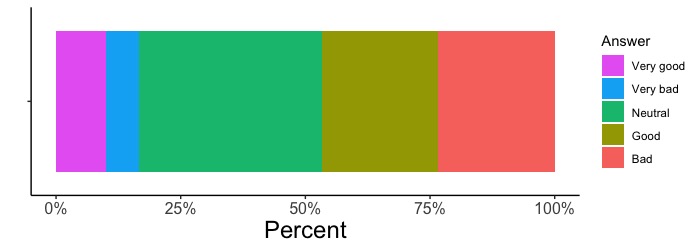
# 音声の聞き取りやすさのアンケート結果を作図しましょう。データフレームx3に、早口の場合のアンケート結果が入っています。Answeが聴き取りやすさ、Freqがそれぞれの回答数です。

ggplot(x3, aes(x = "", y = Freq, fill = Answer)) +
geom_bar(stat = "identity", position = "fill")
# 1つの図しか描かないのでx軸を指定しません。
# データ列Freqに、Very good, Good, Neutral, Bad, Very badの各回答数が入っています。y = Freqとして、描く数値のデータ列にFreqを指定します。
# データ列Answerに、Very good, Good, Neutral, Bad, Very badという回答の名称が記述されています。回答ごとに色分けをします。fill = Answerとして、色分けに用いるデータ列にAnserを指定します。
# position = "fill"として百分率で描きます。
ggplot(x3, aes(x = "", y = Freq, fill = Answer)) +
geom_bar(stat = "identity")
# position = "fill"を指定せず、絶対数で描きます。
# scale_y_continuous(labels = percent)も実行しないで下さい。この命令文は百分率で軸を示すものですので、絶対数の場合に使うことができません。

データ列に入っている各項目の数を集計して複数の図を描く場合
ggplot(データフレーム名, aes(x = データ群の名称が入ったデータ列名, fill = 各項目数の集計および帯の色分けに用いるデータ列名)) +
geom_bar(position = "fill")
# ggplot
# 作図に用いるデータフレームを指定します。
# 複数のデータ群の図を描く場合は、データ群の名称が入ったデータ列名をx軸として指定します。xは小文字です。
# y軸を指定する必要はありません。何も書かなくてよいです(y = ""とする必要もありません)。
# fill =で、各項目数の集計および帯の色分けに用いるデータ列を指定します。これで、y軸を指定したことにもなります。
# geom_bar
# 各項目の数を集計する場合はstat = "identity"の指定は不要です。
# position = "fill"と指定すると、各回答数の割合(百分率)を表示します。fillを""で囲みます。この命令文を省略してgeom_bar()すると、各回答数の絶対数を表示します。円グラフに変換する場合はposition = "fill"を省略してよいです。
# 実行例
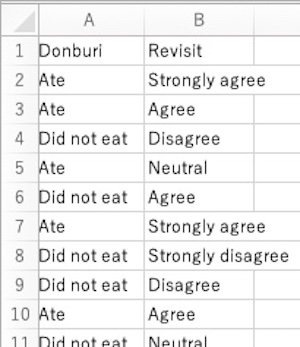
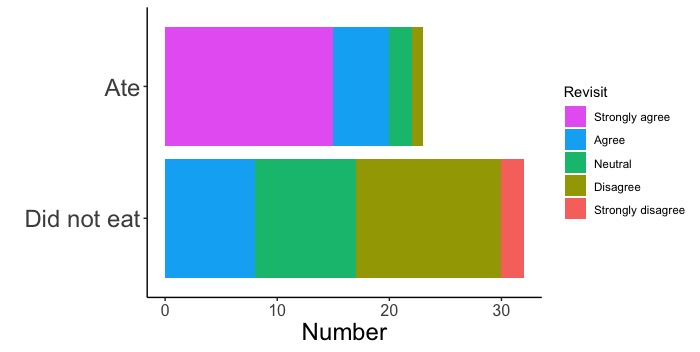
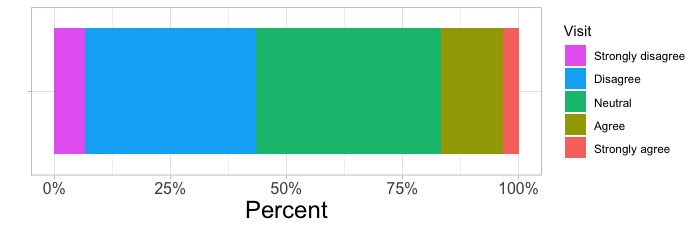
# ○○町にまた行きたいかどうかのアンケート結果を作図しましょう。データフレームdのデータ列Donburiに松茸と秋刀魚の丼を食べたかどうか、Revisitに町にまた行きたいかどうかが入っています。
ggplot(d, aes(x = Donburi, fill = Revisit)) +
geom_bar(position = "fill")
# x = Donburiとして、松茸と秋刀魚の丼を食べたかどうか(AteかDid not eatか)が入っているデータ列Donburiをx軸に指定します。
# fill = Revisitと指定します。この指定により、データ列Revisitをy軸として扱います。データ列Revisitには、Strongly agree, Agree, Neutral, Disagree, Strongly disagreeという回答が入っています。各回答の数を集計し、回答ごとに色分けをして作図します。
# position = "fill"として百分率で描きます。

ggplot(d, aes(x = Donburi, fill = Revisit)) +
geom_bar()
# position = "fill"を指定せず、絶対数で描きます。
# scale_y_continuous(labels = percent)も実行しないで下さい。この命令文は百分率で軸を示すものですので、絶対数の場合に使うことができません。
データ列に入っている各項目の数を集計して1つの図を描く場合
ggplot(データフレーム名, aes(x = "", fill = 各項目数の集計および帯の色分けに用いるデータ列名)) +
geom_bar(position = "fill")
# ggplot
# 作図に用いるデータフレームを指定します。
# 1つの図を描く場合はx軸を指定しません。x = ""とします。xは小文字です。""の中は空です。
# y軸を指定する必要もありません。何も書かなくてよいです(y = ""とする必要もありません)。
# fill =で、各項目数の集計および帯の色分けに用いるデータ列を指定します。これで、y軸を指定したことにもなります。
# geom_bar
# 各項目の数を集計する場合はstat = "identity"の指定は不要です。
# position = "fill"と指定すると、各回答数の割合(百分率)を表示します。fillを""で囲みます。この命令文を省略してgeom_bar()すると、各回答数の絶対数を表示します。円グラフに変換する場合はposition = "fill"を省略してよいです。
# 実行例
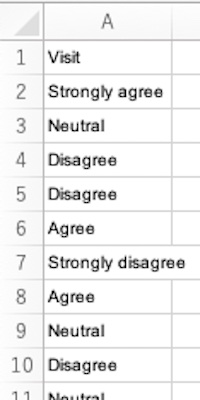
# ○○町に観光に行きたいかどうかのアンケート結果を作図しましょう。データフレームdのデータ列Visitに観光に行きたいかどうかが入っています。
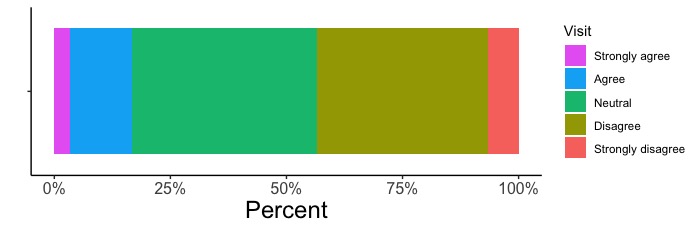
ggplot(d, aes(x = "", fill = Visit)) +
geom_bar(position = "fill")
# fill = Visitと指定します。この指定により、データ列Visitをy軸として扱います。データ列Visitには、Strongly agree, Agree, Neutral, Disagree, Strongly disagreeという回答が入っています。各回答の数を集計し、回答ごとに色分けをして作図します。
# position = "fill"として百分率で描きます。
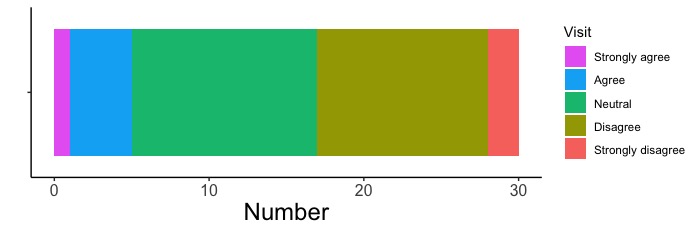
ggplot(d, aes(x = "", fill = Visit)) +
geom_bar()
# position = "fill"を指定せず、絶対数で描きます。
# scale_y_continuous(labels = percent)も実行しないで下さい。この命令文は百分率で軸を示すものですので、絶対数の場合に使うことができません。
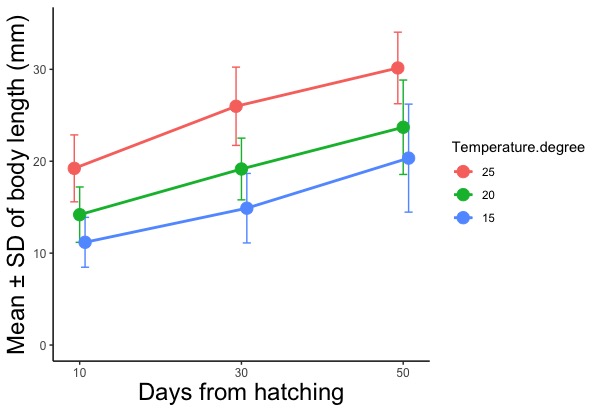
geom_描く図(position = position_dodge(width = ずらす幅))
# 点や線が重なって見難くならないよう、「ずらす幅」だけずらして描きます。
# geom_line(), geom_errorbar, geom_point, geom_histogramなど、描く図を指定する命令文の中で指定します。
# 実行例
geom_line(position = position_dodge(width = 2)) +
geom_errorbar(aes(ymin = Mean.mm - SD.mm, ymax = Mean.mm + SD.mm), position = position_dodge(width = 2))+
geom_point(position = position_dodge(width = 2))
# geom-lineで線の位置を、geom_errorbarで標準偏差の位置を、geom_pointで点の位置を2ずつずらして描かせる。
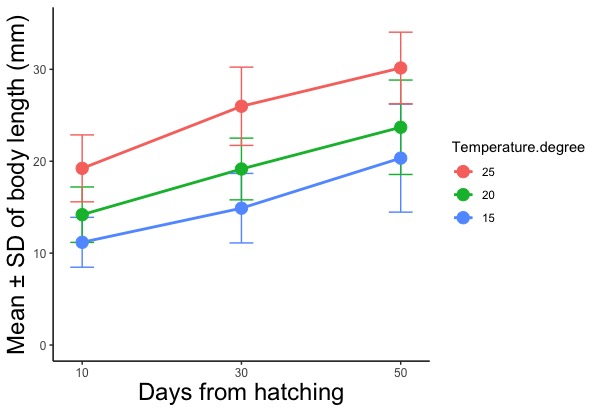
geom_line() +
geom_errorbar(aes(ymin = Mean.mm - SD.mm, ymax = Mean.mm + SD.mm))+
geom_point()
# 何も指定しないと描く位置が重なる。
coord_polar(theta = "y", direction = - 1 または何も書かない)
# 帯グラフを円グラフに変換します。
# theta = "y"と指定し、y軸(fill)に指定したものを円グラフに描きます。yを""で囲みます。yは小文字です。
# direction = - 1と指定すると、データの並び順で指定した順番(指定しなかった場合はアルファベット順)で、各項目が時計回りに配置されます。この命令を書かずにcoord_polar(theta = "y")とすると反時計回りに配置されます。
# 実行例
coord_polar(theta = "y", direction = - 1)
# direction = - 1と指定して時計回りで表示
coord_polar(theta = "y")
# direction = - 1と指定せず反時計回りで表示
scale_y_continuous(labels = percent)
# 回答割合の目盛りをパーセントにします。この命令文を実行しないと0から1の率で示します。
# 実行例
scale_y_continuous(labels = percent)を実行
# パーセントで表示
scale_y_continuous(labels = percent)を省略
# 率で表示

coord_flip()
# 横棒の帯グラフにします。この命令文を省略すると縦棒の帯グラフになります。
# 実行例
coord_flip()を実行
# 横棒に
oord_flip()を省略
# 縦棒に

guides(fill = guide_legend(reverse = TRUE))
# 図本体右横の凡例の並びを逆順にします。この命令文を実行しないと、データの並び順で指定した順番に並びます。
# 実行例
guides(fill = guide_legend(reverse = TRUE))を実行
# データの並び順で指定したものと逆順に
guides(fill = guide_legend(reverse = TRUE))を省略
# データの並び順で指定した順番に
theme_デザインの名称()
# 図を枠線で囲うか、背景色をどうするかなどを指定します。theme_classic(), theme_void(), theme_test(), theme_minimal(), theme_light()など色々あります。試してみて下さい。
# 末尾の()を忘れずに書いて下さい。フォントを指定するときにこの()内に書き込みます。theme_classic(base_family = "HiraKakuPro-W3")というようにです。フォントを指定しない場合は()内は空欄でよいです。
# 円グラフを描くときには必ずtheme_void()を指定して下さい。
# 実行例
theme_classic()
# 左と下に枠がつきます。
theme_test()
# 全体を枠で囲います。

theme_light()
# 背景に目盛り線がつきます。


theme_void()
# 枠で囲いません。

labs(x = "x軸の名称", y = "y軸の名称")
# 図に描き込む、x軸・y軸の名称を指定します。名称を""で囲みます。x = ""とするとx軸の名称を描かず、y = ""とするとy軸の名称を描きません。x, yは小文字です。
# 実行例
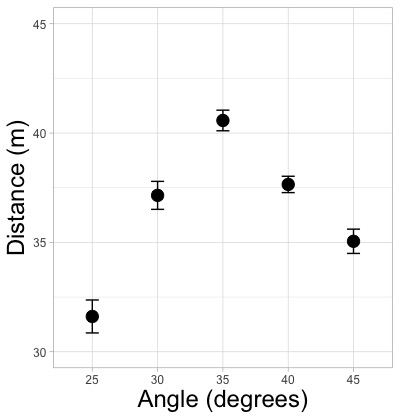
labs(x = "Angle (degrees)", y = "Distance (m)")
# x軸(横軸)の名称をAngle (degrees)に、y軸(縦軸)の名称をDistance (m)にします。
labs(x = "", y = "Caffeine concentration (mg/100g)")
# x軸(横軸)の名称を書かず、y軸(縦軸)の名称をCaffeine concentration (mg/100g)にします。Cofffee, Green tea, Black teaはx軸の名称ではなく、x軸のデータ群名です。
scale_x_discrete(labels = c("群名1", "群名2", "群名3"))
# x軸にデータ群名を書き込みます。x軸に指定したデータ列に入っている各データ群の名称を書きます。データ群の数だけ名称を並べます。データの並び順(あなたが指定した並び順またはアルファベット順)通りに名称を並べて下さい。並びが異なっていたらデータの対応がおかしくなります。名称を""で囲みます。
# 実行例
scale_x_discrete(labels = c("Coffee", "Green tea", "Black tea"))
# x軸(横軸)の各データ群名としてCoffee, Green tea, Black teaを書き込みます。
scale_x_continuous(limits=c(x軸で描く値の最小値, x軸で描く値の最大値), breaks=seq(x軸の目盛りの最小値, x軸の目盛りの最大値, x軸の目盛りの刻み幅))
scale_y_continuous(limits=c(y軸で描く値の最小値, y軸で描く値の最大値), breaks=seq(y軸の目盛りの最小値, y軸の目盛りの最大値, y軸の目盛りの刻み幅))
# limits = で、x軸・y軸で描く値の最小値と最大値を指定します。最小値から最大値の間のみを描き、外側は描きません。
# breaks = で、x軸・y軸の目盛りの最小値・最大値・刻み幅を指定します。目盛りに関する指定であって、上述の描く範囲の指定とは異なります。
# 実行例
scale_x_continuous(limits = c(10, 50))
scale_y_continuous(limits = c(0, 40))
# x軸(横軸)を描く範囲を10から50に指定します。
# y軸(縦軸)を描く範囲を0から40に指定します。
# breaksの指定を省略しているので、描く範囲内に自動で目盛りを描いています。
scale_x_continuous(breaks=seq(0,9,1))
scale_y_continuous(limits = c(0, 50))
# x軸(横軸)の目盛りとして、0から9の1刻みを指定します。limitsの指定を省略しているので、点が存在する範囲全てを自動で描いています。
# y軸(縦軸)を描く範囲を0から50に指定します。breaksの指定を省略しているので、描く範囲内に自動で目盛りを描いています。
theme(
axis.title.x = element_text(size = x軸の名称の文字の大きさ, angle = 書く角度, hjust = 書く位置),
axis.text.x = element_text(size = x軸の目盛りの文字の大きさ, angle = 書く角度, hjust = 書く位置),
axis.title.y = element_text(size = y軸の名称の文字の大きさ, angle = 書く角度, hjust = 書く位置),
axis.text.y = element_text(size = y軸の目盛りの文字の大きさ, angle = 書く角度, hjust = 書く位置)
)
# x軸(横軸)・y軸(縦軸)の名称および目盛りの文字の大きさと書き方を指定します。
# angle = で書く角度を指定します。指定することがあるのはx軸の目盛りに対してです。他は指定しなくてよいです。
# angle = 0;水平に書きます。
# angle = 90;下から上へ垂直に書きます。
# angle = - 90;上から下へ垂直に書きます。
# hjust =で書く位置を指定します。0以上1以下の数値を指定します。指定することがあるのはx軸の目盛りに対してです。他は指定しなくてよいです。
# hjust = 0;左(水平の場合)または下(垂直の場合)に寄せて書きます。
# hjust = 0.5;中央に書きます。
# hjust = 1;右(水平の場合)または上(垂直の場合)に寄せて書きます。
# 必ず、図のデザイン(theme_classic()など)の後に指定します。
theme_classic() +
theme(
axis.title.x = element_text(size = x軸の名称の文字の大きさ),
axis.text.x = element_text(size = x軸の目盛りの文字の大きさ),
axis.title.y = element_text(size = y軸の名称の文字の大きさ),
axis.text.y = element_text(size = y軸の目盛りの文字の大きさ)
)
というようにです。図のデザインの前に指定してしまうと、図のデザインに上書きされて指定が無効になります。
# 実行例
theme(
axis.title.x = element_text(size = 18),
axis.text.x = element_text(size = 9),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸(横軸)・y軸(縦軸)の名称(axis.title.x, axis.title.y)の文字の大きさを18に、x軸・y軸の目盛り(axis.text.x, axis.text.y)の文字の大きさを9に指定します。
theme(
axis.text.x = element_text(size = 18, angle = 90, hjust = 1),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸の目盛りに入っている名称を、下から上へ垂直に描きます。上に寄せます。
theme(
axis.text.x = element_text(size = 18, angle = 90, hjust = 0),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸の目盛りに入っている名称を、下から上へ垂直に描きます。下に寄せます。
theme(
axis.text.x = element_text(size = 18, angle = - 90, hjust = 0.5),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸の目盛りに入っている名称を、上から下へ垂直に描きます。中央配置にします。
facet_wrap(~ データ群の名称が入ったデータ列名, ncol = 列数 または nrow = 行数)
# facet_wrap()と命令することで、複数のデータ群のデータを、別々の図として並べて描くことができます。この命令をしないと、複数のデータ群のデータが一枚の図に描かれます。
# データ群の名称が入ったデータ列に入っているデータ群ごとに図を描きます。冒頭の~を忘れないで下さい。
# ncol, nrowのどちらかを使って図の並べ方を指定します。ncol = で列数を指定します。nrow = で行数を指定します。両方を同時に指定する必要はありません。
# 実行例
facet_wrap(~ Locality, ncol = 1)
# データ列Localityに入っている地域ごとの図を描きます。図を縦1列に並べて描きます。
facet_wrap(~ Locality, nrow = 1)
# 図を横1列に並べて描きます。

facet_wrap(~ Locality, ncol = 2)
# 図を2列に並べて描きます。

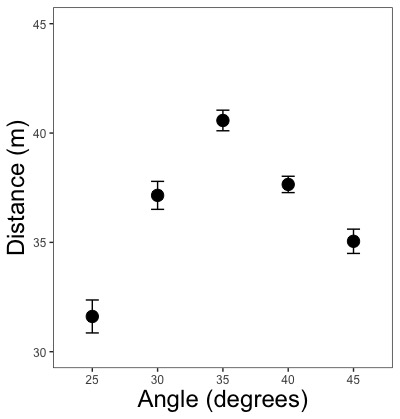
geom_errorbar(aes(ymin = 平均の値 - 標準偏差・標準誤差の値, ymax = 平均の値 + 標準偏差・標準誤差の値), width = 横棒の長さ, linewidth = 縦棒・横棒の太さ, color = "縦棒・横棒の色の英語名")
# 標準偏差・標準誤差を描き込みます。
# ymin =, ymax =で、標準偏差・標準誤差の縦棒の下端と上端の値を指定します。平均の値 - 標準偏差・標準誤差の値を下端に、平均の値 + 標準偏差・標準誤差の値を上端に指定します。
# width =で、横棒の幅を指定します。0より大で1以下の数値を指定して下さい。指定しないと自動で描きます。
# linewidth =で縦棒・横棒の太さを指定します。指定しないと自動で描きます。
# color =で縦棒・横棒の色を指定します。"red", "blue", "white"などです。英語名を""で囲みます。指定しないと黒で描きます。点グラフや棒グラフにおける、作図に用いるデータフレームとデータの指定において色分けを指定した場合は、geom_errorbarでcolorを指定しないで下さい。指定すると、色が上描きされておかしなことになります。
# 実行例
# yに平均値が、zに、標準偏差または標準誤差が入っています。
geom_errorbar(aes(ymin = y - z, ymax = y + z), width = 0.1)
# 横棒の長さを0.1にします。
geom_errorbar(aes(ymin = y - z, ymax = y + z), width = 0.5)
# 横棒の長さを0.5にします。

geom_errorbar(aes(ymin = y - z, ymax = y + z), linewidth = 2, color = "red")
# 縦棒・横棒の太さを2に、色を赤にします。

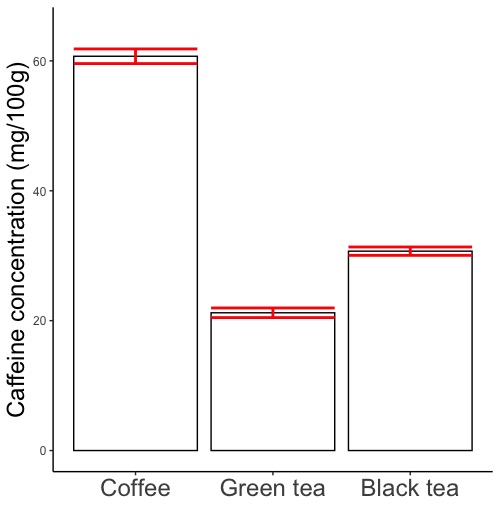
geom_errorbar(aes(ymin = y - z, ymax = y + z))
# 何も指定せず自動で描かせます。
geom_smooth(method = lm, size = 回帰線の太さ, color = "回帰線の色の英語名", linetype = "回帰線の種類の英語名", se = FALSE)
# 回帰式を描かせます。
# size =で線の太さを指定します。指定しないと自動で描きます。
# color =で線の色を指定します。"red", "blue", "green"などです。英語名を""で囲みます。指定しないと青で描きます。
# linetype =で線の種類を指定します。英語名を""で囲みます。指定しないと実線で描きます。
# linetype = "solid";実線 "dashed";破線 "dotted";点線
# se = FALSEと指定すると信頼区間を描きません。この指定をしないと信頼区間を描きます。
# 実行例
geom_smooth(method = lm, size = 2, color = "red", linetype = "dashed", se = FALSE)
# 太さ2の赤い破線で回帰式を描きます。
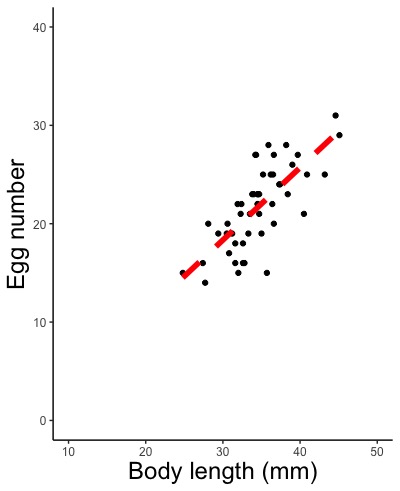
geom_smooth(method = lm)
# 何も指定せず自動で描かせます。信頼区間(灰色の部分)というものも描きます。
検定の命令文
データ間に対応がある場合
方法1
t.test(データフレーム名$検定するデータ列名 ~ データフレーム名$データ群の名称が入ったデータ列名, paired = TRUE)
方法2
t.test(データフレーム名$検定するデータ列名1, データフレーム名$検定するデータ列名2, paired = TRUE)
データ間に対応がない場合
方法1
t.test(データフレーム名$検定するデータ列名 ~ データフレーム名$データ群の名称が入ったデータ列名)
方法2
t.test(データフレーム名$検定するデータ列名1, データフレーム名$検定するデータ列名2)
# 方法1では、データフレームに2種類のみのデータ(たとえば、Night, Morningのみ)が入っている必要があります。
# 方法2では、データフレームに3種類以上(たとえば、Night, Midday, Morningの3種類)入っていてもよいです。そして、その内の2つを指定して検定します。
# データ間に対応がある場合はpaired = TRUEを付け、対応がない場合は付けません。
平均値に差があるかどうかの判定
# データ間に対応がある場合もない場合も以下のように判定します。「有意」とは、「統計的に意味がある」ということです。
P値が0.05以下;平均値に有意な差があると判定
P値が0.05より大;平均値に有意な差はないと判定
# 方法1の実行例
# 以下のファイルを、データフレームdに読み込んで解析します。単語の記憶を、就寝前(Night)と起床後(Morning)に行ったときの試験成績(Score)が入っています。Studentは生徒の番号です。
# 対応のあるt検定
t.test(d$Score ~ d$Timeframe, paired = TRUE)
# データ列Timeframeに記載されているNight, Morning間で、データ列Scoreの平均値の違いを検定します。データの並び順に基づいて対応させます。Night, Morningそれぞれで同じ順番のものが同じ生徒の成績です。
# 検定結果です。
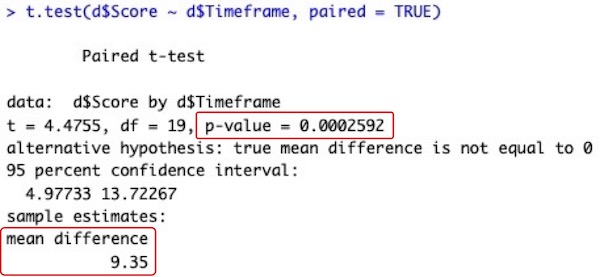
# 左下の赤枠内の「mean difference 9.35」が平均値の差です。就寝前(Night)・起床後(Morning)の順に並べているので、「就寝前 – 起床後」という引き算です。並べた順で引き算をします。
# 右上の赤枠内の「p-value = 0.0002592」がP値です。0.05以下なので、平均値に有意な差があると判定します。
# 対応のないt検定
t.test(d$Score ~ d$Timeframe)
# データ列Timeframeに記載されているNight, Morning間で、データ列Scoreの平均値の違いを検定します。データの対応付けは行いません。
# 検定結果です。

# 下の赤枠内に、就寝前(Night)と起床後(Morning)の平均値が出ています。
# 上の赤枠内の「p-value = 0.01755」がP値です。0.05以下なので、平均値に有意な差があると判定します。
# 方法2の実行例
# 以下のファイルを、データフレームdに読み込んで解析します。
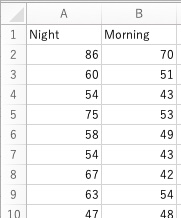
# 対応のあるt検定
t.test(d$Night, d$Morning, paired = TRUE)
# データ列Night, Morning間で平均値の違いを検定します。データの並び順に基づいて対応させます。同じ生徒の成績が同じ行に入っています。
# 検定結果は方法1とまったく同じです。
# 対応のないt検定
t.test(d$Night, d$Morning)
# データ列Night, Morning間で平均値の違いを検定します。データの対応付けは行いません。
# 検定結果は方法1とまったく同じです。
shapiro.test(データ列名)
# そのデータ列のデータが正規分布をしているかどうかを検定します。データ間に対応がある場合もない場合もこのやり方で検定します。
# 帰無仮説;正規分布をしている
# 対立仮説;正規分布をしていない
# P値が0.05よりも大きければ、帰無仮説を棄却できないため、正規分布をしていると判定します。
# P値が0.05以下であれば、帰無仮説を棄却し、正規分布をしていないと判定します。
# この検定を、比較する母集団それぞれについて行います。両母集団とも正規分布をしていると判定できた場合のみt検定を行うことができます。どちらか一つでも正規分布をしていない場合はt検定を行うことはできません。
# 実行例
# 以下のファイルを、データフレームdに読み込んで解析します。単語の記憶を、就寝前(Night)と起床後(Morning)に行ったときの試験成績(Score)が入っています。Studentは生徒の番号です。
x1 <- filter(d, Timeframe == "Night")
x2 <- filter(d, Timeframe == "Morning")
# データフレームdのデータ列Timeframeに、その試験成績が就寝前(Night)なのか起床後(Morning)なのかが記されています。就寝前(Night)のデータを取りだしてデータフレームx1に格納します。起床後(Morning)のデータを取りだしてx2に格納します。
shapiro.test(x1$Score)
shapiro.test(x2$Score)
# データフレームx1のデータ列Score(x1$Score)に就寝前(Night)の試験成績が入っています。データフレームx2のデータ列Score(x2$Score)に起床後(Morning)の試験成績が入っています。それぞれが正規分布をしているかどうかを検定します。
# 検定結果です。
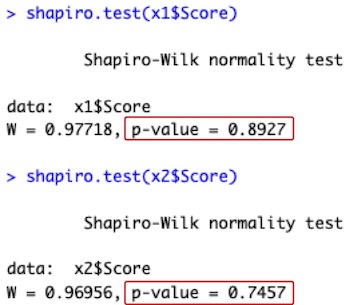
# 上の赤枠内の「p-value = 0.8927」が就寝前の試験成績のP値です。下の赤枠内の「p-value = 0.7457」が起床後の試験成績のP値です。どちらも0.05よりも大きいので、両方とも正規分布をしていると判定します。
glm(formula = 応答変数 ~ 説明変数, family = 確率分布(link = 連結関数), data = データフレーム名)
# 実行例
r <- glm(formula = Length.mm ~ Locality, family = gaussian(link = identity), data = d)
summary(r)
# メダカの体長を地域間で比較します。データフレームdに、体長(Length.mm)と生育地域(Locality)のデータが格納されています。
# 応答変数;体長(Length.mm)
# 説明変数;生育地域(Locality)
# 確率分布;正規分布(gaussian)
# 連結関数;比例(identity)
# 一般化線形モデルによる解析結果をデータフレームrに格納します。
# summary(r)を実行して、解析結果rの詳細を表示させます。
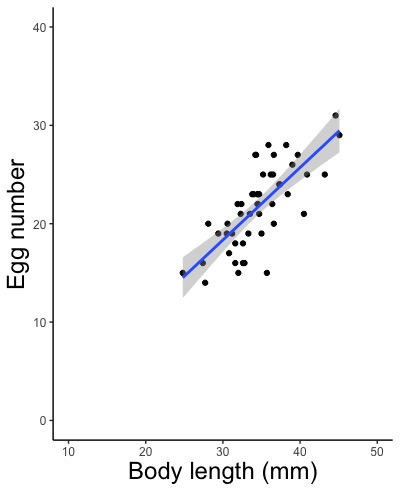
r <- glm(formula = Egg.number ~ Length.mm, family = Gamma(link = log), data = d)
summary(r)
# メダカの体長と産卵数の関係を比較します。データフレームdに、産卵数(Egg.number)と体長(Length.mm)のデータが格納されています。
# 応答変数;産卵数(Egg.number)
# 説明変数;体長(Length.mm)
# 確率分布;ガンマ分布(Gamma)
# 連結関数;指数(log)
# 一般化線形モデルによる解析結果をデータフレームrに格納します。
# summary(r)を実行して、解析結果rの詳細を表示させます。
説明変数が範疇で、比較する対象が3つ以上の場合のみ実行します。emmeansをインストールして読み込んでおく必要があります(emmeansのインストールと読み込みを参照)。
pairs(emmeans(解析結果を格納したデータフレーム名,"説明変数"), adjust="holm")
# 前もって、一般化線形モデルの命令文を実行し、その解析結果をデータフレームに格納しておきます。
# 数値のデータであっても範疇として扱うこともあります。たとえば、ペットボトルロケットの飛行距離を発射角度25, 30, 35, 40, 45間で比較する場合、「25度」「30度」「35度」「40度」「45度」という条件間での比較となります。こうした比較は、「明るい場所」と「暗い場所」の比較といった範疇間での比較と同質です。そのため、説明変数は範疇であるとします。
# adjust="holm"を忘れずに書いて下さい。
# 実行例
r <- glm(formula = Length.mm ~ Locality, family = gaussian(link = identity), data = d)
pairs(emmeans(r,"Locality"), adjust="holm")
# メダカの体長を地域間で比較します。データフレームdに、体長(Length.mm)と生育地域(Locality)のデータが格納されています。
# 応答変数;体長(Length.mm)
# 説明変数;生育地域(Locality)
# 確率分布;正規分布(gaussian)
# 連結関数;比例(identity)
# 一般化線形モデルによる解析結果をデータフレームrに格納します。
# Localityに、Tohoku, Kanto, Kansai, Kyushuという4つの地域が入っています。各地域間で平均体長に差があるのかどうかを検定するために、pairs(emmeans(r,"Locality"), adjust="holm")を実行します。
stat_smooth(method = glm, method.args = list(family = 解析で指定した確率分布(link = 解析で指定した連結関数)), size = 回帰線の太さ, color = "回帰線の色の英語名", linetype = "回帰線の種類の英語名", se = FALSE)
# 一般化線形モデルで得た回帰式を描き込みます。
# 必ず、一般化線形モデルの命令文で指定したものと同じ確率分布・連結関数を指定して下さい。そうでないと、解析で得られた回帰式とは異なる回帰式を描いてしまいます。
# size =で線の太さを指定します。指定しないと自動で描きます。
# color =で線の色を指定します。"red", "blue", "green"などです。英語名を""で囲みます。指定しないと青で描きます。
# linetype =で線の種類を指定します。英語名を""で囲みます。指定しないと実線で描きます。
# linetype = "solid";実線 "dashed";破線 "dotted";点線
# se = FALSEと指定すると信頼区間を描きません。この指定をしないと信頼区間を描きます。
# 実行例
stat_smooth(method = glm, method.args = list(family = gaussian(link = identity)), size = 2, color = "red", linetype = "dashed", se = FALSE)
# 太さ2の赤い破線で回帰式を描きます。
# 確率分布は正規分布(gaussian)、連結関数は比例(identity)です。
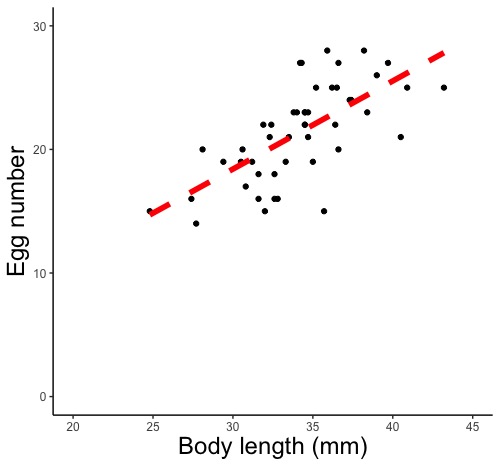
stat_smooth(method = glm, method.args = list(family = gaussian(link = identity)))
# 何も指定せず自動で描かせます。信頼区間(灰色の部分)というものも描きます。
# 確率分布は正規分布(gaussian)、連結関数は比例(identity)です。

y = ax + bの場合;y ~ x または y ~ x + 1
# 条件の変化の影響を解析するときに用います。説明変数xの値が変化すると応答変数がどう変化するのかを解析します。数字の1は切片を意味します。1を書いても書かなくてもよいです。どちらでも解析結果は同じになります。
y = bの場合;y ~ 1
# 1つの条件下でのデータしか無い場合です。その条件下でのデータの状態を解析します。数字の1を必ず書いて下さい。
# 実行例
Flying.distance.m ~ Angle.degree または Flying.distance.m ~ Angle.degree + 1
# ペットボトルロケットの発射角度がAngle.degreeに、飛行距離がFlying.distance.mに入っています。
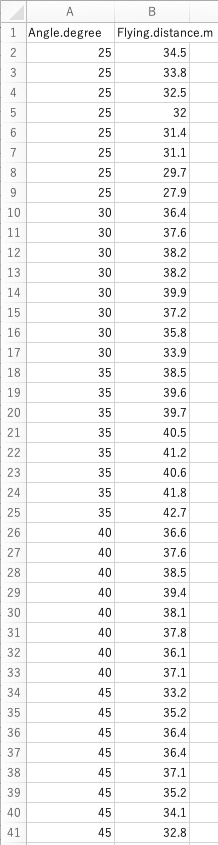
# 発射角度が変化すると飛行距離がどう変化するのかを解析します。
cbind(Light, Dark) ~ 1
# ある1つの条件の下で、ミドリムシが明るい方に移動するのか暗い方に移動するのかを調べました。この実験を複数回行い、各実験における移動個体数がcbind(Light, Dark)に以下のように入っています。左の列が、明るい方に移動した個体数、右の列が、暗い方に移動した個体数です。

# この1つの条件下での移動の偏りを解析します。