これから研究を始める高校生と指導教員のために 第2版
探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方
(これ研)
副読文書
******* V-3. データの値がそもそもばらつく対象の解析 *******
1種類のデータの解析の仕方
--- ミドリムシの走光性 --
(「これ研」本文の第3部3.3.3項;p.96)

「これから研究を始める高校生と指導教員のために 第2版;探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方」(これ研)の第3部3.3.3項「1種類のデータの解析の仕方」(p. 96)で行っている解析と作図を、Rを使って行う方法の解説です。ミドリムシの走行性を例に、移動先という1種類のデータの解析の仕方を説明します。「これ研」の第3部第3章「データの値がそもそもばらつく対象の解析」(p. 83)を読んで、こうした対象の解析について理解しておいて下さい。
RStudioを起動して下さい。起動方法の詳しい説明は、RStusioの起動の仕方を参照して下さい。そして、作業ディレクトリの指定の説明に従って作業ディレクトリを指定します。
setwd("/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析")
# パソコン内での作業ディレクトリの位置がわかっている場合はこの方法が便利です。作業ディレクトリの位置の知り方は作業ディレクトリの表示を参照して下さい。あなたの作業ディレクトリの位置を""で囲んで書きます。この命令文を実行しておきます。
# 作業ディレクトリの位置がわからない(あるいは、上記の説明の意味がわからない)場合は、作業ディレクトリの指定の説明に従って指定して下さい。
作図にはtidyverseというものを用います。tidyverseをインストールしてありますか? まだならば、作図の準備の説明に従ってインストールして下さい。インストールしたら、tidyverseをRに読み込みます。
library(tidyverse)
# RStudioを起動しこの命令文を実行しておきます。Rstudio起動後、一度だけ実行すればよいです。Rstudioを終了して再び起動したときは再実行する必要があります。
解析では、データフレームの中の特定のデータ列を指定することを行います。指定の方法です。
データフレーム名$データ列名
# データフレーム名を書き、$を挟んで、指定したいデータ列名を書きます。
# 実行例
d$Angle.degree
d$Flying.distance.m
# データフレームdに入っているデータ列Angle.degree, flying.distance.mを指定します。
1. 解析に用いるcsvファイルのRヘの読み込み
csvファイル「Light.csv」(画面1)に、ミドリムシの走光性実験の結果が入っています(架空データです)。Experiment.numberが実験番号(10回行った内の何回目か)、Lightが、明るい方に行った個体数、Darkが、暗い方に行った個体数です。このcsvファイルのデータを使って解析と作図を行います。
画面1
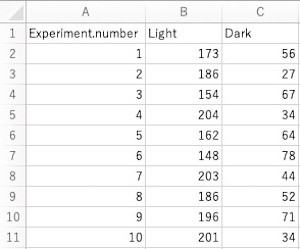
このcsvファイルをダウンロードして、あなたの作業ディレクトリに入れて下さい(作業ディレクトリの指定を参照)。
ご自身のデータを用いる場合は、そのデータが入ったcsvファイルを作業ディレクトリに入れて下さい。先頭行は必ずデータ名にして、続く行に個々のデータを書いて下さい。すべて、半角英数字で書いて下さい(日本語を入れない)。Excelで作ったファイルをcsvファイルに変換する方法は、Excelで作った解析用ファイルのcsv形式での保存を参照して下さい。
csvファイルをRに読み込み、データフレームに格納します。
d <- read.csv("Light.csv")
# csvファイル「Light.csv」を読み込んでデータフレームdに格納します。ファイル名を""で囲みます。ファイル名の拡張子「.csv」も忘れずに書きます。
# データフレームの名称(この例ではd)はお好みのものでよいです。
2. 作図;ミドリムシの走光性
「これ研」本文の図3.13; p. 97
tidyverseを使っての作図の仕方を説明します。tidyverseをRに読み込んでいますか? 読み込んでいない場合は、library(tidyverse)を実行して読み込んで下さい。
作図の命令文の基本です。
ggplot(データフレーム名, aes(データ)) +
geom_描く図の英語名() +
書式の命令文 +
書式の命令文
# ggplotで、用いるデータを指定します。
# geom_で、描く図を指定します。
# 書式の命令文を+で繋げます。いくつでも繋げることができます。最後の命令文の後に+は不要です。
以下では、図の軸の説明が英語の図を描きます。しかし、日本語の論文・プレゼンテーションに使う図の説明文は日本語にしましょう。日本語にする場合の説明も添えているので参照して下さい。
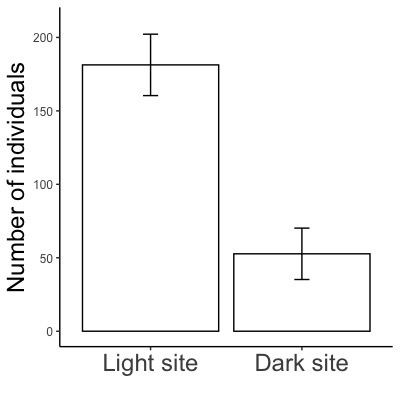
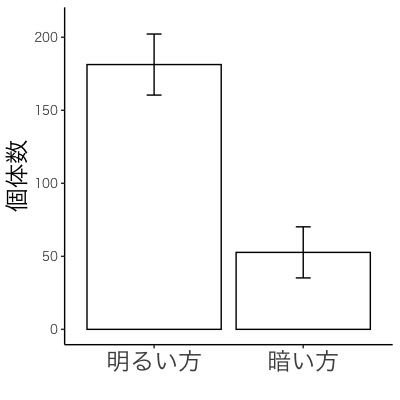
ミドリムシにおける走光性実験の結果の棒グラフ(画面2-1, 2-2)を作図しましょう。
画面2-1
画面2-2
まず始めに、作図に用いる値(個体数の平均と標準偏差)を計算してデータフレームに格納します。
x <- c("Light site", "Dark site")
# 明るさLight site, Dark siteをデータフレームxに格納します。文字情報なので名称を""で囲みます。
# 格納するデータフレームの名称(この例ではx)はお好みのものでよいです。
y <- c(mean(d$Light), mean(d$Dark))
# データフレームdのデータ列Lightに明るい場所に集まった個体数が、データ列Darkに、暗い場所に集まった個体数が入っています。明るい場所(d$Light)と暗い場所(d$Dark)それぞれに集まった個体数の平均を計算し、データフレームyに格納します。mean()で平均を計算します。()内に計算したいデータを入れます。
# データフレームxでの順番と同じ順に明るさを並べて下さい(この例では、Light, Darkの順番にする)。並びが異なるとデータの対応がおかしくなります。
# 格納するデータフレームの名称(この例ではy)はお好みのものでよいです。
z <- c(sd(d$Light), sd(d$Dark))
# 明るい場所(d$Light)と暗い場所(d$Dark)それぞれに集まった個体数の標準偏差を計算し、データフレームzに格納します。sd()で標準偏差を計算します。()内に計算したいデータを入れます。
# データフレームxでの順番と同じ順に明るさを並べて下さい(この例では、Light, Darkの順番にする)。並びが異なるとデータの対応がおかしくなります。
# 格納するデータフレームの名称(この例ではz)はお好みのものでよいです。
d2 <- data.frame(x, y, z)
# x, y, zのデータを統合してデータフレームd2に格納します。格納するデータフレームの名称(この例ではd2)はお好みのものでよいです。
d2$x <- factor(d2$x, levels = c("Light site", "Dark site"))
# 明るさの並び順を指定します。データフレームd2中のデータ列xに明るさの名称が入っています。並べたい順番に名称を書きます。明るさは文字情報なので、明るさを""で囲みます。
# d2$xの中身を上書きするためにd2$xに再格納します。
# この命令を実行しないとアルファベット順に並びます。
# データフレームd2はこうなっています。

格納したデータを用いて棒グラフを作図します。
# 命令文が続く場合には+で繋げ、最後の命令文の後には+を付けません。
# 必須命令文
ggplot(d2, aes(x = x, y = y)) +# データフレームd2を指定します。
# x = xとして、明るさ(Light siteがDark siteか)が入っているデータ列xをx軸に指定します。「x =」のxは小文字です。Light site, Dark siteのデータをx軸に並べて描きます。
# y = yとして、個体数のデータが入っているデータ列yをy軸に指定します。「y =」のyは小文字です。
# 末尾の+を忘れないで下さい。
# 棒グラフにおける、作図に用いるデータフレームとデータの指定
geom_bar(stat = "identity", color = "black", fill = "white") +
# 描く図として棒グラフを指定します。
# color = で、棒の枠線の色を指定します。黒に指定しています。
# fill =で、棒の内部の色を指定します。白に指定しています。
# stat = "identity"を忘れずに書いて下さい。
# 末尾の+を忘れないで下さい。
# 棒グラフの指定
geom_errorbar(aes(ymin = y - z, ymax = y + z), width = 0.1) +
# 標準偏差を描きます。
# ymin =, ymax =で、標準偏差の縦棒の下端と上端の値を指定します。平均 – 標準偏差(y - z)から平均+標準偏差(y + z)まで縦棒を描きます。
# width =で上下の横棒の幅を指定します。0.1にしています。
# 末尾の+を忘れないで下さい。ただし、以降の命令文を省略する場合は+を付けず、「geom_errorbar(aes(ymin = y - z, ymax = y + z), width = 0.1)」とします。
# 省略してもよい命令文
# 以降の命令文を省略するとデフォルトで自動で描きます。
labs(x = "", y = "Number of individuals") +
# x軸(横軸)の名称は書かず、y軸(縦軸)の名称をNumber of individualsにします。名称を""で囲みます。x, yは小文字です。
scale_y_continuous(limits = c(0, 210)) +
# y軸(縦軸)を描く範囲を0から210に指定します。棒グラフの場合は、y軸の最小値を必ず0にします。
theme_classic() +
# 図の背景色を白にします。
theme(
axis.text.x = element_text(size = 18),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸(横軸)の目盛り(axis.text.x)には明るさ(Light siteかDark site)が入っています。明るさとy軸(縦軸)の名称(axis.title.y)の文字の大きさを18に、y軸の目盛り(axis.text.y)の文字の大きさを9に指定します。x軸(横軸)の名称(axis.title.x)は書かないので、その文字の大きさも指定しません。
画面2-2のように軸の説明を日本語にする場合は、2つの命令文(下記の1つ目と3つ目)を書き替え、1つの命令文(下記の2つ目)を書き足します。他の命令文はそのままでよいです。
labs(x = "", y = "個体数") +
# x軸(横軸)の名称は書かず、y軸(縦軸)の名称を「個体数」にします。名称を""で囲みます。x, yは小文字です。
scale_x_discrete(labels = c("明るい方", "暗い方")) +
# 書き足す命令文です。labs(x = "", y = "個体数") +の次に書いて下さい。
# x軸(横軸)の各データ群名として「明るい方」「暗い方」を書き込みます。d2$xでの並び順(あなたが指定した並び順またはアルファベット順)通りに並べて下さい。並びが異なっていたらデータの対応がおかしくなります。文字情報なので名称を""で囲みます。
theme_classic(base_family = "HiraKakuPro-W3") +
# 日本語のフォントとしてHiraKakuPro-W3を指定します。フォントの名称を""で囲みます。
# HiraKakuPro-W3の他にも、HiraKakuPro-W6, Meiryo, MS Gothic, Osakaなど色々なフォントがあります。お好みのフォントを設定して下さい。