これから研究を始める高校生と指導教員のために 第2版
探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方
(これ研)
副読文書
******* VI-3. アンケート結果の示し方 *******
選択肢から1つを選んで回答(複数選択が不可)
異なる設問の間での回答の関係性を見る場合
--- 町の名物を食べたかどうかと、
町にまた行きたいかどうかの関係性 ---

本章では、以下のようなアンケートの結果のまとめ方を説明します。
・選択肢から1つを選んで回答して貰う(複数選択が不可)。
・複数の設問をし、ある設問に対してある回答をした人が、別の設問に対してどう回答するのかを調べることが目的。
たとえば、「松茸と秋刀魚の丼」の観光効果を調べるため、この丼を食べたかどうかと、町をまた訪れたいかどうかをアンケートしたとします。そして、食べたかどうかで、町をまた訪れたいかどうかが異なるのかを調べるとします。
こうしたアンケートでは、帯グラフで回答の分布を比較します。回答の比較は、円グラフよりも帯グラフの方がわかりやすいからです。複数のアンケート結果を作図して比較します。
「松茸と秋刀魚の丼」に関するアンケート結果(「これ研」には載っていません)を例に説明します。「これ研」の第3部第4章「アンケート結果の示し方」(p. 98)を読んで、アンケート結果の示し方を理解しておいて下さい。
RStudioを起動して下さい。起動方法の詳しい説明は、RStusioの起動の仕方を参照して下さい。そして、作業ディレクトリの指定の説明に従って作業ディレクトリを指定します。
setwd("/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析")
# パソコン内での作業ディレクトリの位置がわかっている場合はこの方法が便利です。作業ディレクトリの位置の知り方は作業ディレクトリの表示を参照して下さい。あなたの作業ディレクトリの位置を""で囲んで書きます。この命令文を実行しておきます。
# 作業ディレクトリの位置がわからない(あるいは、上記の説明の意味がわからない)場合は、作業ディレクトリの指定の説明に従って指定して下さい。
作図にはtidyverseというものを用います。tidyverseをインストールしてありますか? まだならば、作図の準備の説明に従ってインストールして下さい。インストールしたら、tidyverseをRに読み込みます。
library(tidyverse)
# RStudioを起動しこの命令文を実行しておきます。Rstudio起動後、一度だけ実行すればよいです。Rstudioを終了して再び起動したときは再実行する必要があります。
scalesというものも作図に用います。scalesをRに読み込みます。scalesはRに備わっているので、インストールする必要はありません。
library(scales)
# この命令文を実行しておきます。Rstudio起動後、一度だけ実行すればよいです。Rstudioを終了して再び起動したときは再実行する必要があります。
解析では、データフレームの中の特定のデータ列を指定することを行います。指定の方法です。
データフレーム名$データ列名
# データフレーム名を書き、$を挟んで、指定したいデータ列名を書きます。
# 実行例
d$Angle.degree
d$Flying.distance.m
# データフレームdに入っているデータ列Angle.degree, flying.distance.mを指定します。
1. 解析に用いるcsvファイルのRへの読み込み
googleフォームで、松茸と秋刀魚の丼に関するアンケート(画面1)を行ったとします。観光客に、この丼を食べたかどうかと、町をまた訪れたいかどうかを訊ねました。
画面1
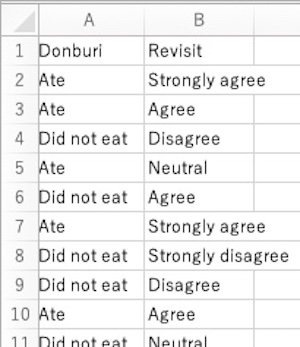
このアンケート結果を、csvファイル「Donburi.csv」(画面2)に保存しました(架空データです)。Rで解析作図をするために英語にしています。松茸と秋刀魚の丼(Donburi)を食べた(Ate)か食べなかった(Did not eat)か、町をまた訪れたいか(Revisit)に対して、「強くそう思う(Strongly agree)」「そう思う(Agree)」「どちらとも言えない(Neutral)」「思わない(Disagree)」「まったく思わない(Strongly disagree)という回答を書いています。同じ行の回答が同じ回答者によるものです。このcsvファイルのデータを使って作図を行います。
画面2
このcsvファイルをダウンロードして、あなたの作業ディレクトリに入れて下さい(作業ディレクトリの指定を参照)。
ご自身のデータを用いる場合は、そのデータが入ったcsvファイルを作業ディレクトリに入れて下さい。先頭行は必ずアンケート項目(Donburi, Revisitなど)にして、続く行に回答を書いて下さい。すべて、半角英数字で書いて下さい(日本語を入れない)。Excelで作ったファイルをcsvファイルに変換する方法は、Excelで作った解析用ファイルのcsv形式での保存を参照して下さい。
csvファイルをRに読み込み、データフレームに格納します。
d <- read.csv("Donburi.csv")
# csvファイル「Donburi.csv」を読み込んでデータフレームdに格納します。ファイル名を""で囲みます。ファイル名の拡張子「.csv」も忘れずに書きます。
# データフレームの名称(この例ではd)はお好みのものでよいです。
2. 作図
tidyverseとscalesを使っての作図の仕方を説明します。これらをRに読み込んでいますか? 読み込んでいない場合は、tidyverseのRへの読み込みとscalesのRへの読み込みを実行して読み込んで下さい。
作図の命令文の基本です。
ggplot(データフレーム名, aes(データ)) +
geom_描く図の英語名() +
書式の命令文 +
書式の命令文
# ggplotで、用いるデータを指定します。
# geom_で、描く図を指定します。
# 書式の命令文を+で繋げます。いくつでも繋げることができます。最後の命令文の後に+は不要です。
2.1. 円グラフの作図(基礎情報として)
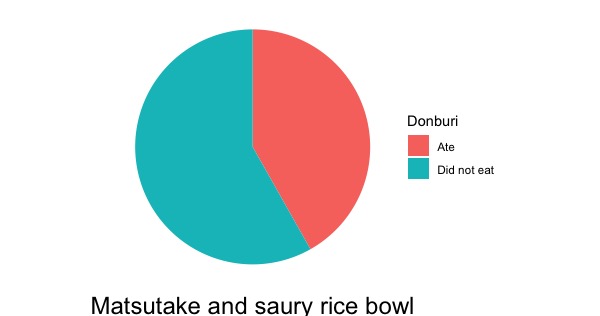
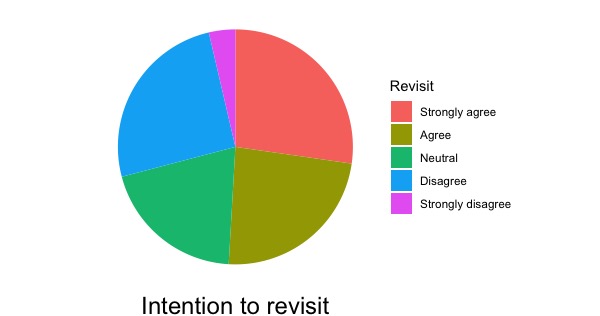
基礎情報として、松茸と秋刀魚の丼を食べたかどうか、町をまた訪れたいかどうか(丼を食べた人と食べなかった人を合わせての回答)それぞれへの回答を円グラフ(画面3-1, 3-2)で見るとします。両グラフ間で回答の分布を比較するのではなく、各グラフ内での回答分布を見たいだけなので、帯グラフではなく円グラフにします(帯グラフでもよいのですが)。画面2のデータを用いて作図します。
画面3-1
画面3-2
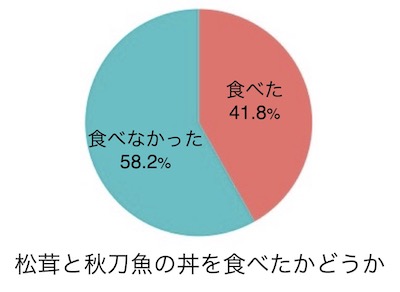
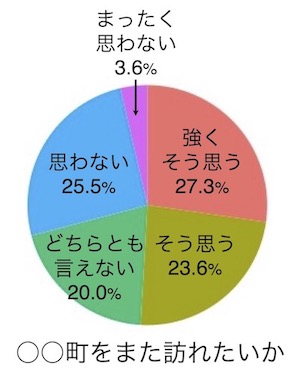
Rでは画面3-1を作図します。この図を、PowerPoint等に読み込んで画面3-2に加工します(Rでもこうした加工は出来るのですが、難しいので、PowerPointでやってしまいましょう)。日本語の論文・プレゼンテーションならば説明文も日本語にします。英語部分は白く塗りつぶすなり切り取るなりして、そこに日本語を書いて下さい。回答(「強くそう思う」等)も円グラフの中に書き込みます。
作図の前に、画面2のデータの並び順を指定しておきます。
d$Revisit <- factor(d$Revisit, levels = c("Strongly agree", "Agree", "Neutral", "Disagree", "Strongly disagree"))
# 回答の並び順を指定します。データフレームd中のデータ列Donburiに、松茸と秋刀魚の丼を食べたかどうかの回答の名称が、データ列Revisitに、町をまた訪れたいかどうかの回答の名称が入っています。並べたい順番に回答の名称を書きます。文字データなので、名称を""で囲みます。
# d$Donburi, d$Revisitの中身を上書きするためにd$Donburi, d$Revisitに再格納します。
# この命令を実行しないとアルファベット順に並びます。1つ目は、アルファベット順に並んでいるので実は指定不要です。指定の仕方の説明のために書いておきました。
円グラフは、帯グラフを描いてから、それを円グラフに変換するという方法で作図します。
# 命令文が続く場合には+で繋げ、最後の命令文の後には+を付けません。
# 町をまた訪れたいかどうか(Revisit)を例に説明します。松茸と秋刀魚の丼を食べたかどうかの作図は、RevisitをDonburiに入れ替えて行ってください。
# 必須命令文
ggplot(d, aes(x = "", fill = Revisit)) +# データフレームdを指定します。
# 1つの図を描く場合はx軸を指定しません。x = ""とします。xは小文字です。""の中は空です。
# fill = Revisitと指定します。この指定により、データ列Revisitをy軸として扱います。データ列Revisitには、Strongly agree, Agree, Neutral, Disagree, Strongly disagreeという回答が入っています。各回答の数を集計し、回答ごとに色分けをして作図します。
# 末尾の+を忘れないで下さい。
# 帯グラフにおける、作図に用いるデータフレームとデータの指定、および帯グラフの指定;データ列に入っている各項目の数を集計して1つの図を描く場合
geom_bar() +
# 描く図として、まずは帯グラフを指定します。
# 末尾の+を忘れないで下さい。
# 帯グラフにおける、作図に用いるデータフレームとデータの指定、および帯グラフの指定;データ列に入っている各項目の数を集計して1つの図を描く場合
coord_polar(theta = "y", direction = - 1) +
# 円グラフに変換します。
# theta = "y"と指定し、y軸として指定したFreqを描くようにします。yを""で囲みます。yは小文字です。
# direction = - 1は、聴き取りやすさへの回答(Very good等)を時計回りに配置するという指定です。データの並び順で指定した順番で時計回りに配置します。これを省略すると反時計回りに配置されます。
# 末尾の+を忘れないで下さい。ただし、以降の命令文を省略する場合は+を付けず、「coord_polar(theta = "y", direction = - 1)」とします。
# 省略してもよい命令文
# 以降の命令文を省略するとデフォルトで自動で描きます。
labs(x = "", y = "Intention to revisit") +
# 図の名称をIntention to revisitにします。x軸の名称は描かず、y軸の名称をIntention to revisitと指定します。名称を""で囲みます。x, yは小文字です。
theme_void() +
# 図の背景色を白にします。余計な軸等も描かせないため、theme_void()を指定します。
theme(axis.title.x = element_text(size = 18))
# 図の名称(Intention to revisit)の文字の大きさを18に指定します。axis.title.xであってaxis.title.yではないので注意してください。
軸の説明文(Intention to revisit)を日本語にする場合は、2つの命令文を書き替えます。他の命令文はそのままでよいです。
画面3-1の右にある回答項目(Strongly agreeなど)を日本語にするのはPowerPointで行うのが手っ取り早いです。英語部分は白く塗りつぶすなり切り取るなりして、そこに日本語を書いて下さい。
labs(x = "", y = "○○町をまた訪れたいか") +
# x軸(横軸)の名称は書かず、y軸(縦軸)の名称を「○○町をまた訪れたいか」にします。名称を""で囲みます。x, yは小文字です。
theme_classic(base_family = "HiraKakuPro-W3") +
# 日本語のフォントとしてHiraKakuPro-W3を指定します。フォントの名称を""で囲みます。
# HiraKakuPro-W3の他にも、HiraKakuPro-W6, Meiryo, MS Gothic, Osakaなど色々なフォントがあります。お好みのフォントを設定して下さい。
# 出来上がった図(画面3-1)をPowerPoint等に読み込んで加工するために、丼を食べたかどうか(Donburi)・町をまた訪れたいか(Revisit)それぞれにおける各回答の割合を計算します。そして(画面3-2)のような図に加工します。PowerPoint等への図の読み込み方は、図の保存・コピーの仕方を参照して下さい。
prop.table(table(d$Donburi))
prop.table(table(d$Revisit))

# データフレームdのデータ列Donburi, Revisitに入っている各回答の割合を計算します。
2.2. 帯グラフの作図
いよいよ本番です。画面2のデータを使って、松茸と秋刀魚の丼を食べた人と食べなかった人それぞれにおける、町をまた訪れたいかどうかの回答分布(画面4-1, 4-2)を作図します。
画面4-1
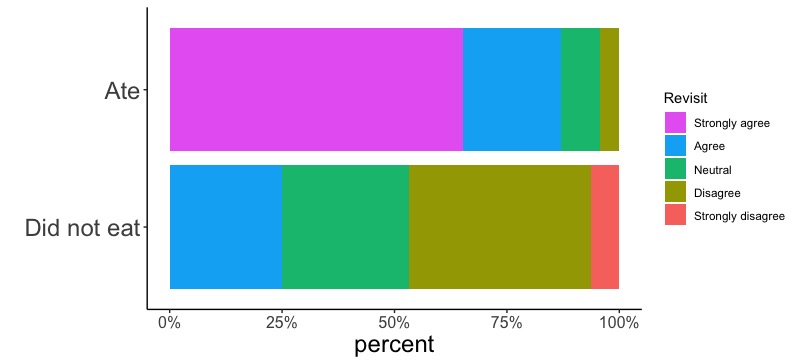
画面4-2
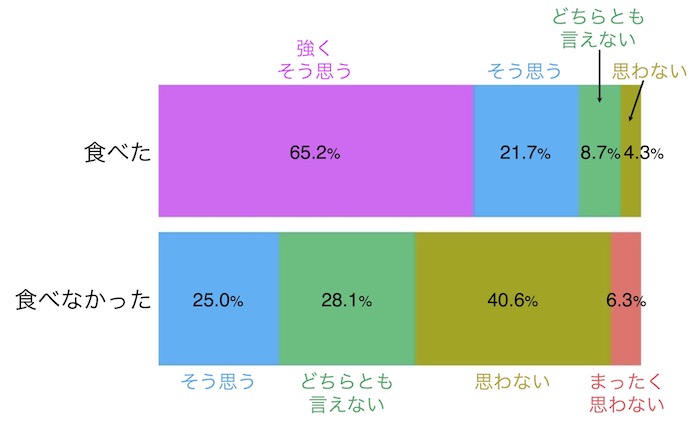
Rでは画面4-1を作図します。この図を、PowerPoint等に読み込んで画面4-2に加工します(Rでもこうした加工は出来るのですが、難しいので、PowerPointでやってしまいましょう)。日本語の論文・プレゼンテーションならば説明文も日本語にします。英語部分は白く塗りつぶすなり切り取るなりして、そこに日本語を書いて下さい。回答(「強くそう思う」等)も帯グラフのすぐそばに書き込みます。
作図の前に、画面2のデータの並び順を指定しておきます。横棒の帯グラフにするので、円グラフのときとは逆の順番にします。
d$Donburi <- factor(d$Donburi, levels = c("Did not eat", "Ate"))
d$Revisit <- factor(d$Revisit, levels = c("Strongly disagree", "Disagree", "Neutral", "Agree", "Strongly agree"))
# 回答の並び順を指定します。データフレームd中のデータ列Donburiに、松茸と秋刀魚の丼を食べたかどうかの回答の名称が、データ列Revisitに、町をまた訪れたいかどうかの回答の名称が入っています。並べたい順番に回答の名称を書きます。回答は文字情報なので、回答の名称を""で囲みます。
# d$Donburi, d$Revisitの中身を上書きするためにd$Donburi, d$Revisitに再格納します。
# この命令を実行しないとアルファベット順に並びます。
では作図をします。
# 命令文が続く場合には+で繋げ、最後の命令文の後には+を付けません。
# 必須命令文
ggplot(d, aes(x = Donburi, fill = Revisit)) +# データフレームdを指定します。
# x = Donburiとして、松茸と秋刀魚の丼を食べたかどうか(AteかDid not eatか)が入っているデータ列Donburiをx軸に指定します。xは小文字です。Ate, Did not eatのデータをx軸に並べて描きます。
# fill = Revisitと指定します。この指定により、データ列Revisitをy軸として扱います。データ列Revisitには、Strongly agree, Agree, Neutral, Disagree, Strongly disagreeという回答が入っています。各回答の数を集計し、回答ごとに色分けをして作図します。
# 末尾の+を忘れないで下さい。
# 帯グラフにおける、作図に用いるデータフレームとデータの指定、および帯グラフの指定;データ列に入っている各項目の数を集計して複数の図を描く場合
geom_bar(position = "fill") +
# 描く図として帯グラフを指定します。position = "fill"と指定することで、百分率による作図にします。fillを""で囲みます。この命令文を省略してgeom_bar()すると、各回答の絶対数で作図します。
# 末尾の+を忘れないで下さい。
# 帯グラフにおける、作図に用いるデータフレームとデータの指定、および帯グラフの指定;データ列に入っている各項目の数を集計して複数の図を描く場合
scale_y_continuous(labels = percent) +
# y軸の目盛りをパーセント表記にします。scalesをRに読み込んでおかないとこの命令文を実行できません。この命令文を実行しないと0から1の率で表記します。
# 末尾の+を忘れないで下さい。ただし、以降の命令文を省略する場合は+を付けず、「scale_y_continuous(labels = percent)」とします。
# 省略してもよい命令文
# 以降の命令文を省略するとデフォルトで自動で描きます。
coord_flip() +
# 横棒の帯グラフにします。この命令文を実行しないと縦棒の帯グラフになります。
# 横棒か縦棒かの指定guides(fill = guide_legend(reverse = TRUE)) +
# 図本体右横の凡例の並びを、データの並び順で指定したものと逆順にします。上から、Strongly agree, Agree, Neutral, Disagree, Strongly disagreeの順に並びます。この指定をしないと、Strongly disagree, Disagree, Neutral, Agree, Strongly agreeの順番(データの並び順で指定した順番)に並びます。図本体での並びと合うように、逆順にするかしないかを決めて下さい。
labs(x = "", y = "Percent") +
# 縦軸(横棒にしているので実はx軸)の名称は書かず、横軸(実はy軸)の名称をPercentにします。名称を""で囲みます。x, yは小文字です。
theme_classic() +
# 図の背景色を白にします。
# 図のデザインの指定
theme(
axis.title.x = element_text(size = 18),
axis.text.x = element_text(size = 12),
axis.text.y = element_text(size = 18)
)
# 文字の大きさを指定します。横軸(横棒にしても、なぜかこちらは横軸がx軸のままです)の名称(axis.title.x)の文字の大きさを18に、目盛り(axis.text.x)の文字の大きさを12に指定します。縦軸(これもy軸のまま)の目盛り(axis.title.y)には、松茸と秋刀魚の丼を食べたかどうか(AteかDid not eat)が入っています。その文字の大きさを18に指定します。縦軸(y軸)の名称(axis.text.y)は書かないので、その文字の大きさも指定しません。
軸の説明文(Percent)を日本語にする場合は、2つの命令文を書き替えます。他の命令文はそのままでよいです。
他の部分の英語(Ate,Stgonrly agreeなど)を日本語にするのはPowerPointで行うのが手っ取り早いです。英語部分は白く塗りつぶすなり切り取るなりして、そこに日本語を書いて下さい。
labs(x = "", y = "割合") +
# x軸(横軸)の名称は書かず、y軸(縦軸)の名称を「割合」にします。名称を""で囲みます。x, yは小文字です。
theme_classic(base_family = "HiraKakuPro-W3") +
# 日本語のフォントとしてHiraKakuPro-W3を指定します。フォントの名称を""で囲みます。
# HiraKakuPro-W3の他にも、HiraKakuPro-W6, Meiryo, MS Gothic, Osakaなど色々なフォントがあります。お好みのフォントを設定して下さい。
# 出来上がった図(画面4-1)をPowerPoint等に読み込んで加工するために、丼を食べた人(Ate)食べなかった人(Did not eat)それぞれにおける各回答の割合を計算します。そして(画面4-2)のような図に加工します。PowerPoint等への図の読み込み方は、図の保存・コピーの仕方を参照して下さい。
x1 <- filter(d, Donburi == "Ate")
x2 <- filter(d, Donburi == "Did not eat")
# データフレームdの中から、丼を食べた人(Ate)の回答を取り出しデータフレームx1に格納します。食べなかった人(Did not eat)の回答を取り出しデータフレームx2に格納します。=を2つ繋げ==とすることに注意して下さい。回答は文字情報なので、取り出す回答名を""で囲みます。
prop.table(table(x1$Revisit))
prop.table(table(x2$Revisit))

# データフレームx1, x2のデータ列Revisitに入っている各回答の割合を計算します。