これから研究を始める高校生と指導教員のために 第2版
探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方
(これ研)
副読文書
******* VII. t検定(ウェルチのt検定) *******
--- 単語の記憶成績の記憶時間帯間での比較 ---
(「これ研」本文の第3部6.4節;p. 128)

「これから研究を始める高校生と指導教員のために 第2版;探究活動と課題研究の進め方・論文の書き方・口頭とポスター発表の仕方」(これ研)の第3部6.4節「t検定に挑戦」(p. 128)で行っている解析と作図を、Rを使って行う方法の解説です。t検定(ウェルチのt検定)を、就寝前および起床後における単語記憶の試験結果を例に説明します。「これ研」の第3部第6章「検定に挑戦しよう」(p. 118)を読み、検定とは何かを理解しておいて下さい。
RStudioを起動して下さい。起動方法の詳しい説明は、RStusioの起動の仕方を参照して下さい。そして、作業ディレクトリの指定の説明に従って作業ディレクトリを指定します。
setwd("/Users/sakai/Documents/書籍等原稿/これ研2版/課題研究解析")
# パソコン内での作業ディレクトリの位置がわかっている場合はこの方法が便利です。作業ディレクトリの位置の知り方は作業ディレクトリの表示を参照して下さい。あなたの作業ディレクトリの位置を""で囲んで書きます。この命令文を実行しておきます。
# 作業ディレクトリの位置がわからない(あるいは、上記の説明の意味がわからない)場合は、作業ディレクトリの指定の説明に従って指定して下さい。
作図にはtidyverseというものを用います。tidyverseをインストールしてありますか? まだならば、作図の準備の説明に従ってインストールして下さい。インストールしたら、tidyverseをRに読み込みます。
library(tidyverse)
# RStudioを起動しこの命令文を実行しておきます。Rstudio起動後、一度だけ実行すればよいです。Rstudioを終了して再び起動したときは再実行する必要があります。
解析では、データフレームの中の特定のデータ列を指定することを行います。指定の方法です。
データフレーム名$データ列名
# データフレーム名を書き、$を挟んで、指定したいデータ列名を書きます。
# 実行例
d$Angle.degree
d$Flying.distance.m
# データフレームdに入っているデータ列Angle.degree, flying.distance.mを指定します。
1. t検定の手順
始めに、t検定の手順を説明します。
t検定で解析するデータは、比較する両母集団ともに正規分布をしている必要があります。正規分布をしていない場合はt検定を適用できません。その理由は、「「これから研究を始める高校生と指導教員のために 第2版」の第3部6.4項(p. 128)を参照して下さい。
正規分布とは、左右対称の釣り鐘型の分布をしたものです。
画面1
人間の身長や年平均気温や試験の成績など、実に多くのものが正規分布をします。データ値の分布の仕方としてもっとも普遍的なものです。
得られたデータのヒストグラムを描いてみて(ヒストグラムの描き方)、正規分布をしていそうかどうかを判断しましょう。判断は見た目でよいです。たとえば以下のような分布なら正規分布と判断してよいです(この図のデータは、パソコン上で、正規分布からランダムにデータを取ったものです)。
画面2
正規分布がどうかを調べる検定があるのですが、高校レベルでは使わなくてもよいでしょう。ただし、正規分布かどうかの検定方法を載せていますので、難しそうではないと判断した方は挑戦して下さい。
2. データ間の対応の有無の確認
データ間に対応があるかどうかで検定方法が少し異なります。「対応がある」とは、同じ対象から2種類のデータを取った場合のことをいいます。たとえば同じ生徒に、就寝前および起床後に単語記憶をして貰い、両時間帯の記憶成績を比較するとします。就寝前の成績と起床後の成績は、同一人のものとして対応しています。一方の「対応がない」はこれ以外の場合をいいます。たとえば、東北のメダカと九州のメダカで体長を比較するとします。別々の個体からデータを取るので、データ間に対応関係がありません。あなたのデータが、対応があるものなのかどうかを確認して下さい。
対応がある場合は、データを取った対象の個性の違いを考慮した解析が出来ます。たとえば、記憶力には個人差があります。同じ人の、就寝前と起床後の記憶成績を対応づければ、記憶力の違いを考慮した解析を行うことが出来ます。対応がない場合はこうした解析が出来ません。そのため一般には、対応がある方が平均値の差を検出しやすいです。
3. 作図
ヒストグラムや箱ひげ図を描いて論文やプレゼンテーションで示します。対応があるデータの場合は、対応したデータを線で結びつけた点グラフ(画面5)を描きます。
4. t検定
データ間に対応がある場合は対応のあるt検定を、対応がない場合は対応のないt検定を行います。
では以降で、就寝前および起床後における単語記憶の試験結果の解析を例に説明していきます。
2. 解析に用いるcsvファイルのRへの読み込み
就寝前(Night)および起床後(Morning)に単語記憶をして貰い、両時間帯の記憶成績を比較するとします。その結果を、csvファイル「Memory.csv」(画面3-1)にまとめました(架空データです)。
画面3-1
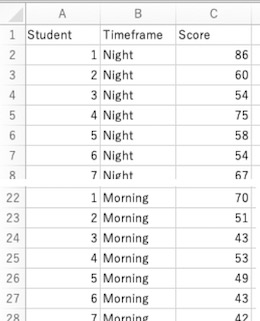
データ列Studentに試験を受けた生徒の番号(同じ番号が同一生徒)が、データ列Timeframeに単語記憶をした時間帯(NightかMorningか)が、Scoreに記憶成績(高いほど良い)が入っています。
このcsvファイルをダウンロードして、あなたの作業ディレクトリに入れて下さい(作業ディレクトリの指定を参照)。
作図をせずにt検定だけを行いたい場合は、画面3-2のcsvファイル(csvファイル「Memory2.csv」)をダウンロードしてもよいです(作図をする場合は、画面3-1のcsvファイルの方が扱いやすいです)。同じ行に同じ生徒の成績が入っています。実はこれは、「これから研究を始める高校生と指導教員のために 第2版」本文で紹介しているファイルです。これをダウンロードして、対応のあるt検定または対応のないt検定をして下さい。
画面3-2
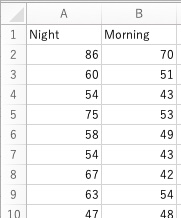
ご自身のデータを用いる場合は、そのデータが入ったcsvファイルを作業ディレクトリに入れて下さい。データ間に対応があり、画面3-1の形式にする場合は、対応関係を示すデータ列(画面3-1ではStudent)を作って下さい。そして必ず、各対象において同じ順番に並べて下さい。画面3で、Night, Morningともに、Student 1, 2, 3, ....と同じ順番で生徒の成績を並べているようにです。画面3-2の形式にする場合は、対応するデータを同じ行に並べて下さい。Excelで作ったファイルをcsvファイルに変換する方法は、Excelで作った解析用ファイルのcsv形式での保存を参照して下さい。
csvファイルをRに読み込み、データフレームに格納します。
d <- read.csv("Memory.csv")
# csvファイル「Memory.csv」を読み込んでデータフレームdに格納します。ファイル名を""で囲みます。ファイル名の拡張子「.csv」も忘れずに書きます。
# 画面3-2のデータのファイル名はMemory2.csvなので、こちらを読み込む場合はd2 <- read.csv("Memory2.csv")として下さい。格納するデータフレーム名も、混乱を避けるために別の名称(たとえばd2)にしておきましょう。
# データフレームの名称(この例ではd, d2)はお好みのものでよいです。
d$Timeframe <- factor(d$Timeframe, levels=c("Night", "Morning"))
# 記憶時間帯の並び順を指定します。データフレームd中のデータ列Timeframeに記憶時間帯が入っています。並べたい順番に記憶時間帯を書きます。記憶時間帯は文字情報なので、記憶時間帯を""で囲みます。
# d$Timeframeの中身を上書きするためにd$Timeframeに再格納します。
# この命令を実行しないとアルファベット順に記憶時間帯が並びます。
# Memory2を読み込んだ場合はこの命令文は不要です。
3. 作図
始めに作図をしましょう。tidyverseを使っての作図の仕方を説明します。tidyverseをRに読み込んでいますか? 読み込んでいない場合は、library(tidyverse)を実行して読み込んで下さい。
作図をする場合はMemory(画面3-1)を読み込んで下さい。Memory2(画面3-2)では以下の命令を実行できません。
作図の命令文の基本です。
ggplot(データフレーム名, aes(データ)) +
geom_描く図の英語名() +
書式の命令文 +
書式の命令文
# ggplotで、用いるデータを指定します。
# geom_で、描く図を指定します。
# 書式の命令文を+で繋げます。いくつでも繋げることができます。最後の命令文の後に+は不要です。
以下では、図の軸の説明が英語の図を描きます。しかし、日本語の論文・プレゼンテーションに使う図の説明文は日本語にしましょう。日本語にする場合の説明も添えているので参照して下さい。
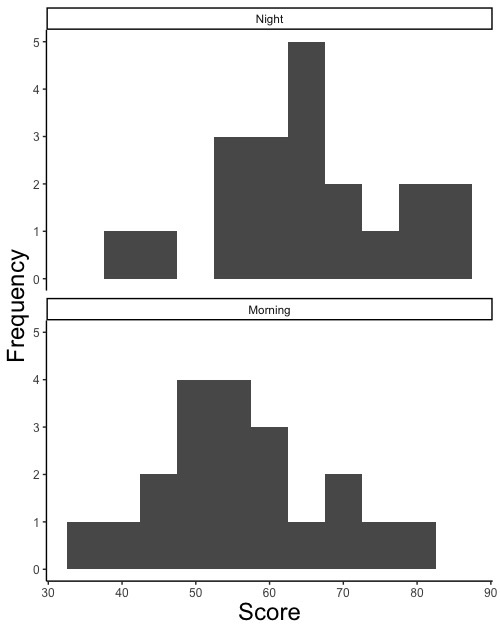
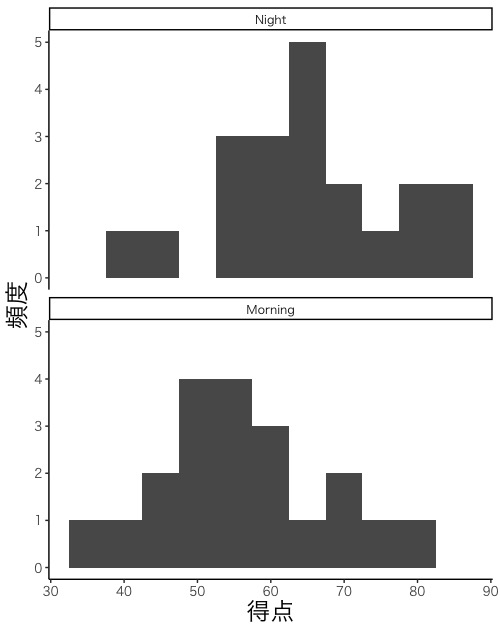
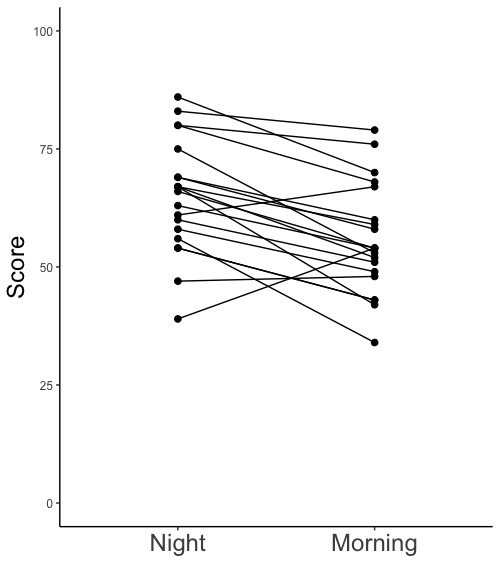
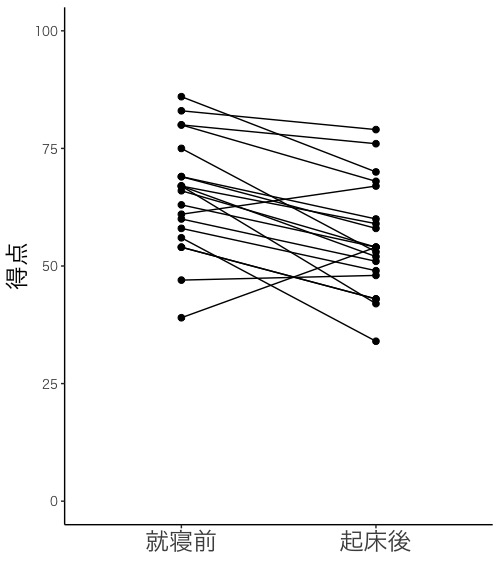
試験成績に関して3種類の図を描きます。一つ目はヒストグラム(画面4-1, 4-2)です。データ間に対応がある場合もない場合も、ヒストグラムを描いて、正規分布をしているかどうかを確認します。二つ目は、同じ生徒の成績を線で結びつけた点グラフ(画面5-1, 5-2)です。データ間に対応がある場合に描きます。三つ目は箱ひげ図(画面6-1, 6-2)です。データ間に対応がない場合に描きます。
論文やプレゼンテーションでは、データ間に対応がある場合は点グラフ(画面5-1, 5-2)を、対応がない場合はヒストグラム(画面4-1, 4-2)か箱ひげ図(画面6-1, 6-2)を示します。
画面4-1
画面4-2
画面5-1
画面5-2
画面6-1
画面6-2
3.1. 就寝前および起床後の単語記憶成績のヒストグラム
就寝前および起床後の単語記憶成績のヒストグラム(画面4-1, 4-2)を描きます。正規分布をしているかどうかの確認に使います。データ間に対応がない場合、論文やプレゼンテーションではこの図か箱ひげ図を示します。
# 命令文が続く場合には+で繋げ、最後の命令文の後には+を付けません。
# 必須命令文
ggplot(d, aes(x = Score)) +# データフレームdを指定します。
# x = Scoreとして、ヒストグラムを描く試験成績のデータ列Scoreをx軸(横軸)に指定します。xは小文字です。
# 末尾の+を忘れないで下さい。
# ヒストグラムにおける、作図に用いるデータフレームとデータの指定
geom_histogram(binwidth = 5) +
# 描く図としてヒストグラムを指定します。
# 個々の横棒の幅を5(5点刻み)に指定します。
# 末尾の+を忘れないで下さい。
facet_wrap(~ Timeframe, ncol = 1) +
# 複数の図(就寝前および起床後のヒストグラム)を並べて描く場合はfacet_wrap()と命令します。
# データ列Timeframeに入っている時間帯ごとにヒストグラムを描きます。Timeframeの前の~を忘れずに書いて下さい。
# 図の並べ方をncol(またはnrow)で指定します。ncol=1にすると縦1列に並びます。
# 末尾の+を忘れないで下さい。ただし、以降の命令文を省略する場合は+を付けず、「facet_wrap(~ Timeframe, ncol = 1)」とします。
# 省略してもよい命令文
# 以降の命令文を省略するとデフォルトで自動で描きます。
labs(x = "Score", y = "Frequency") +
# x軸(横軸)の名称をScoreに、y軸(縦軸)の名称をFrequencyにします。名称を""で囲みます。x, yは小文字です。
scale_y_continuous(limits = c(0, 5)) +
# y軸(縦軸)を描く範囲を0から5に指定します。ヒストグラムの場合は、y軸の最小値を必ず0にします。
theme_classic() +
# 図の背景色を白にします。
theme(
axis.title.x = element_text(size = 18),
axis.text.x = element_text(size = 9),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸(横軸)・y軸(縦軸)の名称(axis.title.x, axis.title.y)の文字の大きさを18に、x軸・y軸の目盛り(axis.text.x, axis.text.y)の文字の大きさを9に指定します。
画面4-2のように軸の説明を日本語にする場合は、以下の2つの命令文を書き替えます。他の命令文はそのままでよいです。
labs(x = "得点", y = "頻度") +
# x軸(横軸)の名称を得点に、y軸(縦軸)の名称を頻度にします。名称を""で囲みます。x, yは小文字です。
theme_classic(base_family = "HiraKakuPro-W3") +
# 日本語のフォントとしてHiraKakuPro-W3を指定します。フォントの名称を""で囲みます。
# HiraKakuPro-W3の他にも、HiraKakuPro-W6, Meiryo, MS Gothic, Osakaなど色々なフォントがあります。お好みのフォントを設定して下さい。
# ヒストグラムの上にあるNight, Morningを日本語にしたい場合は、この図をPowerPoint等に読み込んで修正するのが手っ取り早いです。英語を白く塗りつぶしたり切り取ったりして、日本語を書き込みましょう。PowerPoint等への図の読み込み方は、図の保存・コピーの仕方を参照して下さい。
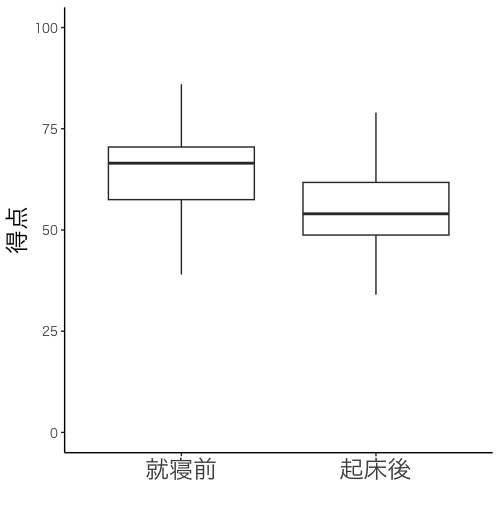
3.2. 同じ生徒の成績を線で結びつけた点グラフ
同じ生徒の成績を線で結びつけた点グラフ(画面5-1, 5-2)を描きましょう。データ間に対応がある場合、論文やプレゼンテーションではこの図を使います。
# 命令文が続く場合には+で繋げ、最後の命令文の後には+を付けません。
# 必須命令文
ggplot(d, aes(x = Timeframe, y = Score, group =Student)) +# データフレームdを指定します。
# x = Timeframeとして、記憶時間帯のデータ列Timeframe(NightかMorningが入っている)をx軸(横軸)に指定します。xは小文字です。
# y = Scoreとして、試験成績のデータ列Scoreをy軸(縦軸)に指定します。yは小文字です。
# group =Studentとして、生徒の番号(同じ番号が同じ生徒)のデータ列Studentをグループ分けに指定します。同じ生徒番号の成績を線で結びつけます。
# 末尾の+を忘れないで下さい。
# 点グラフにおける、作図に用いるデータフレームとデータの指定
geom_line() +
# 描く図として折れ線グラフを指定します。
# 末尾の+を忘れないで下さい。
geom_point(size = 2) +
# 描く図として点グラフも指定します。
# size =で点の大きさを指定します。2にしています。
# 末尾の+を忘れないで下さい。ただし、以降の命令文を省略する場合は+を付けず、「geom_point(size = 2)」とします。
# 省略してもよい命令文
# 以降の命令文を省略するとデフォルトで自動で描きます。
labs(x = "", y = "Score") +
# x軸(横軸)の名称を描かず、y軸(縦軸)の名称をScoreにします。名称を""で囲みます。x, yは小文字です。
scale_y_continuous(limits = c(0, 100)) +
# y軸(縦軸)を描く範囲を0から100に指定します。
theme_classic() +
# 図の背景色を白にします。
theme(
axis.text.x = element_text(size = 18),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸(横軸)の目盛り(axis.text.x)には記憶時間帯(NightかMorningか)が入っています。記憶時間帯とy軸(縦軸)の名称(axis.title.y)の文字の大きさを18に、y軸の目盛り(axis.text.y)の文字の大きさを9に指定します。x軸(横軸)の名称(axis.title.x)は書かないので、その文字の大きさも指定しません。
画面5-2のように軸の説明を日本語にする場合は、2つの命令文(下記の1つ目と3つ目)を書き替え、1つの命令文(下記の2つ目)を書き足します。他の命令文はそのままでよいです。
labs(x = "", y = "得点") +
# x軸(横軸)の名称は書かず、y軸(縦軸)の名称を得点にします。名称を""で囲みます。x, yは小文字です。
scale_x_discrete(labels = c("就寝前", "起床後")) +
# 書き足す命令文です。labs(x = "", y = "得点") +の次に書いて下さい。
# x軸(横軸)の各データ群名として「就寝前」「起床後」を書き込みます。d$Timeframeでの並び順で指定した順番通りに時間帯を並べて下さい。並びが異なっていたらデータの対応がおかしくなります。名称を""で囲みます。
theme_classic(base_family = "HiraKakuPro-W3") +
# 日本語のフォントとしてHiraKakuPro-W3を指定します。フォントの名称を""で囲みます。
# HiraKakuPro-W3の他にも、HiraKakuPro-W6, Meiryo, MS Gothic, Osakaなど色々なフォントがあります。お好みのフォントを設定して下さい。
3.3. 就寝前および起床後の単語記憶成績の箱ひげ図
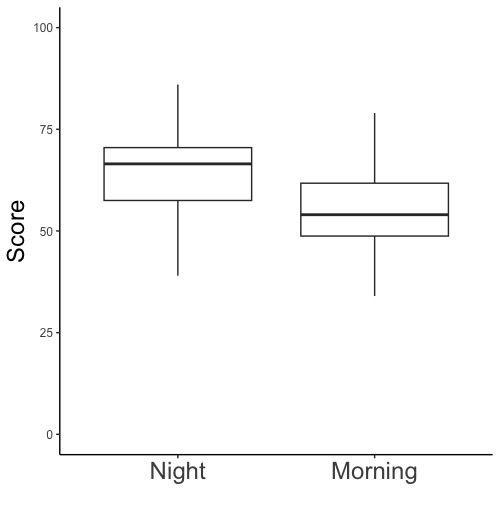
就寝前および起床後の単語記憶成績の箱ひげ図(画面6-1, 6-2)を描きます。データ間に対応がない場合、論文やプレゼンテーションではこの図かヒストグラムを示します。
# 命令文が続く場合には+で繋げ、最後の命令文の後には+を付けません。
# 必須命令文
ggplot(d, aes(x = Timeframe, y = Score)) +
# データフレームdを指定します。
# x = Timeframeとして、記憶時間帯(Timeframe)が入っているデータ列Timeframeをx軸(横軸)に指定します。xは小文字です。
# y = Scoreとして、試験成績(Score)が入っているデータ列Scoreをy軸(縦軸)に指定します。yは小文字です。
# データ列Timeframeに入っている記憶時間帯ごとに、データ列Scoreに入っている試験成績のデータを作図します。
# 末尾の+を忘れないで下さい。
# 箱ひげ図における、作図に用いるデータフレームとデータの指定
geom_boxplot() +
# 描く図として箱ひげ図を指定します。
# 末尾の+を忘れないで下さい。ただし、以降の命令文を省略する場合は+を付けず、「geom_boxplot()」とします。
# 箱ひげ図の指定
# 省略してもよい命令文
# 以降の命令文を省略するとデフォルトで自動で描きます。
labs(x = "", y = "Score") +
# x軸(横軸)の名称は書かず、y軸(縦軸)の名称をScoreにします。名称を""で囲みます。x, yは小文字です。
scale_y_continuous(limits = c(0, 100)) +
# y軸(縦軸)を描く範囲を0から100に指定します。
theme_classic() +
# 図の背景色を白にします。
theme(
axis.text.x = element_text(size = 18),
axis.title.y = element_text(size = 18),
axis.text.y = element_text(size = 9)
)
# x軸(横軸)の目盛り(axis.text.x)には記憶時間帯(Night, Morning)が入っています。記憶時間帯とy軸(縦軸)の名称(axis.title.y)の文字の大きさを18に、y軸の目盛り(axis.text.y)の文字の大きさを9に指定します。x軸(横軸)の名称(axis.title.x)は書かないので、その文字の大きさも指定しません。
画面6-2のように軸の説明を日本語にする場合は、2つの命令文(下記の1つ目と3つ目)を書き替え、1つの命令文(下記の2つ目)を書き足します。他の命令文はそのままでよいです。
labs(x = "", y = "得点") +
# x軸(横軸)の名称は書かず、y軸(縦軸)の名称を得点にします。名称を""で囲みます。x, yは小文字です。
scale_x_discrete(labels = c("就寝前", "起床後")) +
# 書き足す命令文です。labs(x = "", y = "得点") +の次に書いて下さい。
# x軸(横軸)の各データ群名として「就寝前」「起床後」を書き込みます。d$Timeframeでの並び順で指定した順番通りに時間帯を並べて下さい。並びが異なっていたらデータの対応がおかしくなります。名称を""で囲みます。
theme_classic(base_family = "HiraKakuPro-W3") +
# 日本語のフォントとしてHiraKakuPro-W3を指定します。フォントの名称を""で囲みます。
# HiraKakuPro-W3の他にも、HiraKakuPro-W6, Meiryo, MS Gothic, Osakaなど色々なフォントがあります。お好みのフォントを設定して下さい。
4 t検定
就寝前と起床後とで、単語記憶の成績の平均に違いがあるかのかどうかをt検定します。データ間に対応がある場合とない場合のそれぞれを説明します。
「これから研究を始める高校生と指導教員のために 第2版」の第3部6.2節(p. 120)を読み、検定で行うこととP値のことを理解しておいて下さい。
まず始めに、t検定の命令文を説明してしまいましょう。その後に、具体的な検定方法を説明します。
データ間に対応がある場合
方法1
t.test(データフレーム名$検定するデータ列名 ~ データフレーム名$データ群の名称が入ったデータ列名, paired = TRUE)
方法2
t.test(データフレーム名$検定するデータ列名1, データフレーム名$検定するデータ列名2, paired = TRUE)
データ間に対応がない場合
方法1
t.test(データフレーム名$検定するデータ列名 ~ データフレーム名$データ群の名称が入ったデータ列名)
方法2
t.test(データフレーム名$検定するデータ列名1, データフレーム名$検定するデータ列名2)
# 画面3-1の形式なら方法1, 2のどちらも実行できます。画面3-2の形式のでは方法2しか実行できません。
# 画面3-1の形式で方法1を行う場合は、データフレームに2種類のみのデータ(たとえば、Night, Morningのみ)が入っている必要があります。方法2では、元となるデータフレーム(csvファイルを読み込んで格納したデータフレーム)に3種類以上(たとえば、Night, Midday, Morningの3種類)のデータが入っていてもよいです。その内の2種類を指定して検定します。
# データ間に対応がある場合はpaired = TRUEを付け、対応がない場合は付けません。
平均値に差があるかどうかの判定
# データ間に対応がある場合もない場合も以下のように判定します。「有意」とは、「統計的に意味がある」ということです。
P値が0.05以下;平均値に有意な差があると判定
P値が0.05より大;平均値に有意な差はないと判定
# 実行例
t.test(d$Score ~ d$Timeframe, paired = TRUE) # データ間に対応あり;方法1
t.test(x1$Score, x2$Score, paired = TRUE) # データ間に対応あり;方法2
t.test(d$Score ~ d$Timeframe) # データ間に対応なし;方法1
t.test(x1$Score, x2$Score) # データ間に対応なし;方法2
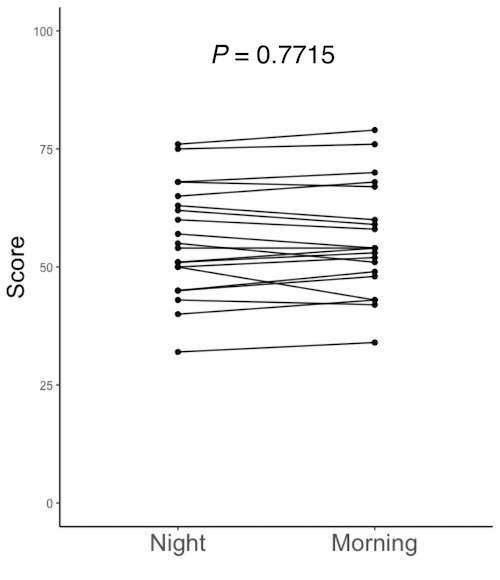
4.1. データ間に対応のあるt検定
データ間に対応のあるt検定を行います。方法1, 2それぞれを説明します。
t.test(d$Score ~ d$Timeframe, paired = TRUE)
# 画面3-1をデータフレームdに読み込んでいます。データフレームdのデータ列Score(d$Score)に、就寝前(Night)と起床後(Morning)の記憶試験の成績が入っています。データフレームdのデータ列Timeframe(d$Timeframe)に、その成績が就寝前(Night)なのか起床後(Morning)なのかが記されています。d$Timeframeに基づいて時間帯を区別し、成績の平均値の差を検定します。
# paired = TRUEと指定して、対応のあるt検定を行います。
# t検定の命令文
# 検定結果です。
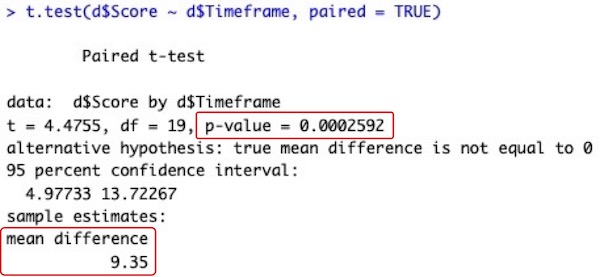
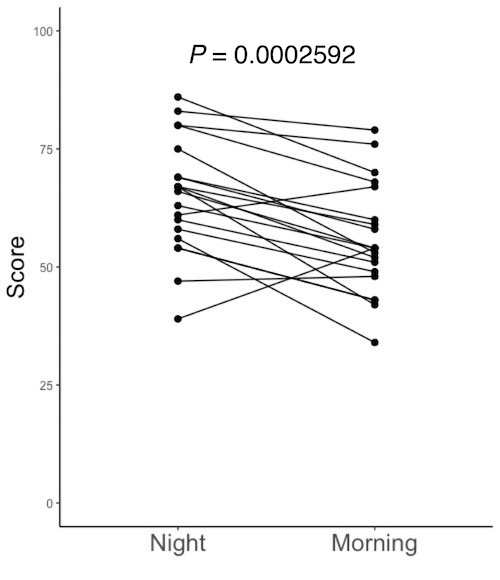
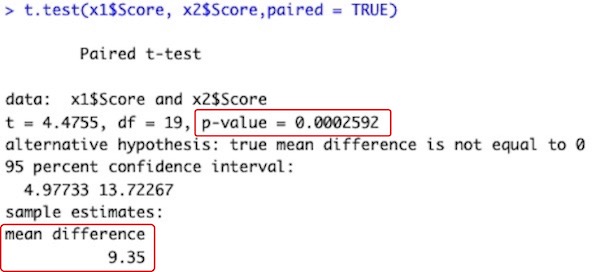
# 左下の赤枠内の「mean difference 9.35」が平均値の差です。就寝前(Night)・起床後(Morning)の順に並べているので、「就寝前 – 起床後」という引き算です。並べた順で引き算をします。
# 右上の赤枠内の「p-value = 0.0002592」がP値です。P値が0.05以下だと、平均値に有意な差があると判定します。「有意」とは、「統計的に意味のある」ということです。論文やプレゼンテーションの文中では、「有意な差があった(P = 0.0002592)」「P = 0.0002592で有意」などと書きます。Rで描いた図をPowerPoint等に読み込んで、図中にも「P = 0.0002592」と書き込みます。PowerPoint等への図の読み込み方は、図の保存・コピーの仕方を参照して下さい。
# P値が0.05よりも大きい場合は平均値に差があったと判定することはできません。たとえばP = 0.7715だったならば、論文やプレゼンテーションの文中では、「有意な差がなかった(P = 0.7715)」「P = 0.7715で有意差なし」などと書きます。Rで描いた図をPowerPoint等に読み込んで、図中にも「P = 0.7715」と書き込みます。PowerPoint等への図の読み込み方は、図の保存・コピーの仕方を参照して下さい。
# 方法1では、データフレームに入っているデータの種類が2つである必要があります。この例では、就寝前(Night)と起床後(Morning)という2種類のデータが入っています。3種類以上のデータ(たとえば、Night, Midday, Morningという3つの時間帯の試験成績)が入っている場合には適用できません。その場合は方法2を用います。
x1 <- filter(d, Timeframe == "Night")
x2 <- filter(d, Timeframe == "Morning")
# 画面3-1をデータフレームdに読み込んでいます。データフレームdのデータ列Timeframeに、その試験成績が就寝前(Night)なのか起床後(Morning)なのかが記されています。就寝前(Night)のデータを取りだしてデータフレームx1に格納します。起床後(Morning)のデータを取りだしてx2に格納します。=を2つ繋げ==とすることに注意して下さい。時間帯は文字情報なので、Night, Morningを""で囲みます。
t.test(x1$Score, x2$Score, paired = TRUE)
# データフレームx1のデータ列Score(x1$Score)に就寝前(Night)の試験成績が、データフレームx2のデータ列Score(x2$Score)に起床後(Morning)の試験成績が入っています。両者の平均値の差を検定します。
# paired = TRUEと指定して、対応のあるt検定を行います。
# t検定の命令文
# 検定結果は、方法1とまったく同じになります。
# 結果の解釈の仕方と図での示し方については、方法1の説明を読んで下さい。
# 方法2は、元となるデータフレーム(この場合はデータフレームd)に入っているデータの種類が3つ以上あっても適用できます。たとえば、Night, Midday, Morningという3つの時間帯の試験成績が入っており、その内のNightとMiddayのデータを取りだして平均値の差を比較するといったことができます。
# あるいは、画面3-2のようにcsvファイル(Memory2.csv)を作った場合にも適用できます。
画面3-2
# 簡素に、就寝前(Night)および起床後(Morning)の試験成績を独立のデータ列に書いています。同じ行の成績が同じ生徒のものです。
# このファイルの場合のt検定は簡単です。
d2 <- read.csv("Memory2.csv")
# Memory2.csvを読み込んでデータフレームd2に格納します。混乱を避けるため、格納するデータフレーム名をd2に変えています。
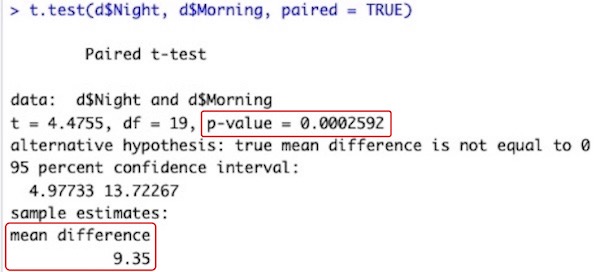
t.test(d2$Night, d2$Morning, paired = TRUE)
# データフレームd2のデータ列Night(d2$Night)に就寝前の試験成績が、データ列Morning(d2$Morning)に起床後の試験成績が入っています。両者の平均値の差を検定します。
# paired = TRUEと指定して、対応のあるt検定を行います。
# 検定結果はまったく同じになります。
4.2. データ間に対応のないt検定
データ間に対応のないt検定を行います。方法1, 2それぞれを説明します。
就寝前(Night)と起床後(Morning)の記憶力試験を行ったのが別人で、両データ間に対応がないとします。
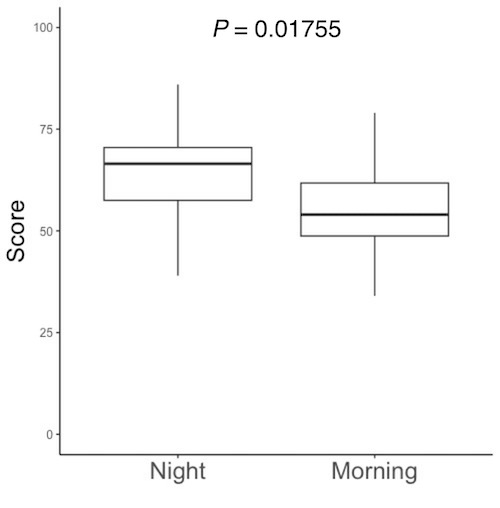
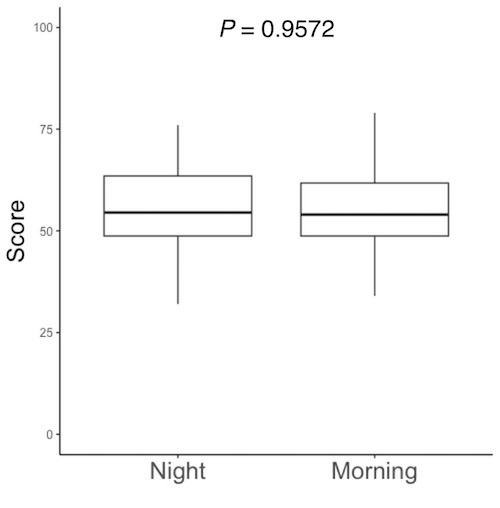
t.test(d$Score ~ d$Timeframe)
# 画面3-1をデータフレームdに読み込んでいます。データフレームdのデータ列Score(d$Score)に、就寝前(Night)と起床後(Morning)の記憶試験の成績が入っています。データフレームdのデータ列Timeframe(d$Timeframe)に、その成績が就寝前(Night)なのか起床後(Morning)なのかが記されています。d$Timeframeに基づいて時間帯を区別し、成績の平均値の差を検定します。
# t検定の命令文
# 検定結果です。

# 下の赤枠内に、就寝前(Night)と起床後(Morning)の平均値が出ています。
# 上の赤枠内の「p-value = 0.01755」がP値です。P値が0.05以下だと、平均値に有意な差があると判定します。「有意」とは、「統計的に意味のある」ということです。論文やプレゼンテーションの文中では、「有意な差があった(P = 0.01755)」「P = 0.01755で有意」などと書きます。Rで描いた図をPowerPoint等に読み込んで、図中にも「P = 0.01755」と書き込みます。PowerPoint等への図の読み込み方は、図の保存・コピーの仕方を参照して下さい。
# P値が0.05よりも大きい場合は平均値に差があったと判定することはできません。たとえばP = 0.9572だったならば、論文やプレゼンテーションの文中では、「有意な差がなかった(P = 0.9572)」「P = 0.9572で有意差なし」などと書きます。Rで描いた図をPowerPoint等に読み込んで、図中にも「P = 0.9572」と書き込みます。PowerPoint等への図の読み込み方は、図の保存・コピーの仕方を参照して下さい。
# 方法1では、データフレームに入っているデータの種類が2つである必要があります。この例では、就寝前(Night)と起床後(Morning)という2種類のデータが入っています。3種類以上のデータ(たとえば、Night, Midday, Morningという3つの時間帯の試験成績)が入っている場合には適用できません。その場合は方法2を用います。
x1 <- filter(d, Timeframe == "Night")
x2 <- filter(d, Timeframe == "Morning")
# 画面3-1をデータフレームdに読み込んでいます。データフレームdのデータ列Timeframeに、その試験成績が就寝前(Night)なのか起床後(Morning)なのかが記されています。就寝前(Night)のデータを取りだしてデータフレームx1に格納します。起床後(Morning)のデータを取りだしてx2に格納します。=を2つ繋げ==とすることに注意して下さい。時間帯は文字情報なので、Night, Morningを""で囲みます。
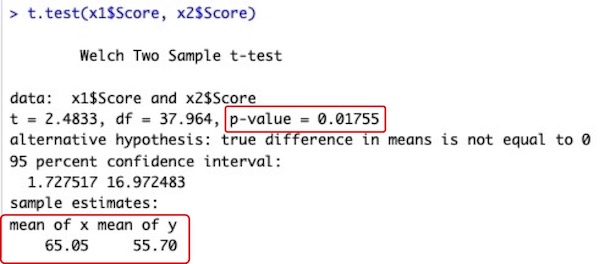
t.test(x1$Score, x2$Score)
# データフレームx1のデータ列Score(x1$Score)に就寝前の試験成績が、データフレームx2のデータ列Score(x2$Score)に起床後の試験成績が入っています。両者の平均値の差を検定します。
# t検定の命令文
# 検定結果は、方法1とまったく同じになります。
# 結果の解釈の仕方と図での示し方については、方法1の説明を読んで下さい。
# 方法2は、元となるデータフレーム(この場合はデータフレームd)に入っているデータの種類が3つ以上あっても適用できます。たとえば、Night, Midday, Morningという3つの時間帯の試験成績が入っており、その内のNightとMiddayのデータを取りだして平均値の差を比較するといったことができます。
# あるいは、画面3-2のようにcsvファイル(Memory2.csv)を作った場合にも適用できます。
画面3-2
# 簡素に、就寝前(Night)および起床後(Morning)の試験成績を独立のデータ列に書いています。ただし、就寝前と起床後の実験を行った生徒は異なり、同じ行の試験成績も別の生徒のものであるとします。
# このファイルの場合のt検定は簡単です。
d2 <- read.csv("Memory2.csv")
# Memory2.csvを読み込んでデータフレームd2に格納します。混乱を避けるため、格納するデータフレーム名をd2に変えています。
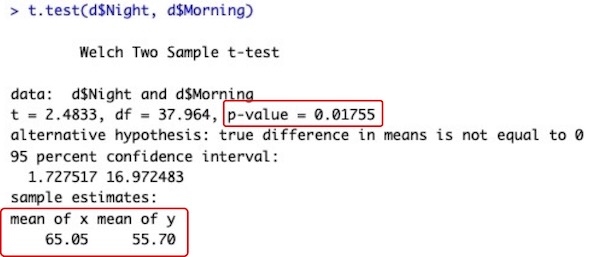
t.test(d2$Night, d2$Morning)
# データフレームd2のデータ列Night(d2$Night)に就寝前の試験成績が、データ列Morning(d2$Morning)に起床後の試験成績が入っています。両者の平均値の差を検定します。
# 検定結果はまったく同じになります。
5 正規分布かどうかの検定
t検定で解析するデータは、比較する両母集団ともに正規分布をしている必要があります。シャピロ・ウィルク検定という手法を用いて、正規分布かどうかを検定する方法を紹介します。
「これから研究を始める高校生と指導教員のために 第2版」の第3部6.2節(p. 120)を読み、検定で行うこととP値のことを理解しておいて下さい。
shapiro.test(データフレーム名$データ列名)
# そのデータ列のデータが正規分布をしているかどうかを検定します。データ間に対応がある場合もない場合もこのやり方で検定します。
# 帰無仮説;正規分布をしている
# 対立仮説;正規分布をしていない
# P値が0.05よりも大きければ、帰無仮説を棄却できないため、正規分布をしていると判定します。
# P値が0.05以下であれば、帰無仮説を棄却し、正規分布をしていないと判定します。
# この検定を、比較する母集団それぞれについて行います。両母集団とも正規分布をしていると判定できた場合のみt検定を行うことができます。どちらか一つでも正規分布をしていない場合はt検定を行うことはできません。
では、検定を実行してみましょう。
x1 <- filter(d, Timeframe == "Night")
x2 <- filter(d, Timeframe == "Morning")
# 画面3-1をデータフレームdに読み込んでいます。データフレームdのデータ列Timeframeに、その試験成績が就寝前(Night)なのか起床後(Morning)なのかが記されています。就寝前(Night)のデータを取りだしてデータフレームx1に格納します。起床後(Morning)のデータを取りだしてx2に格納します。=を2つ繋げ==とすることに注意して下さい。時間帯は文字情報なので、Night, Morningを""で囲みます。
shapiro.test(x1$Score)
shapiro.test(x2$Score)
# データフレームx1のデータ列Score(x1$Score)に就寝前(Night)の試験成績が入っています。データフレームx2のデータ列Score(x2$Score)に起床後(Morning)の試験成績が入っています。それぞれが正規分布をしているかどうかを検定します。
# 検定結果です。
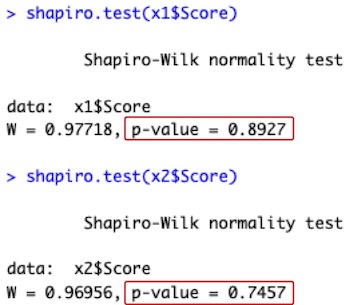
# 上の赤枠内の「p-value = 0.8927」が就寝前の試験成績のP値です。下の赤枠内の「p-value = 0.7457」が起床後の試験成績のP値です。どちらも0.05よりも大きいので、帰無仮説(正規分布をしている)を棄却できません。よって、両方とも正規分布をしていると判定します。
# 画面3-2のようにcsvファイル(Memory2.csv)を作った場合は以下のように検定します。
画面3-2
d2 <- read.csv("Memory2.csv")
# Memory2.csvを読み込んでデータフレームd2に格納します。混乱を避けるため、格納するデータフレーム名をd2に変えています。
shapiro.test(d2$Night)
shapiro.test(d2$Morning)
# 検定結果は、上記とまったく同じになります。